

What is Agent Memory?
Your AI forgets everything the moment you close the tab. Here's how to fix that.

Your customer service agent handles 50 tickets a day. At 3pm, a frustrated customer writes in for the third time this week: “I already explained this twice. My order was supposed to ship Monday.”
Your agent replies: “I’d be happy to help! Could you provide your order number?”
The customer had already given it. Twice. The agent just forgot.
This isn’t a model quality problem. GPT-4, Claude, Gemini: they’re all brilliant inside a single conversation. But the moment that conversation ends, it’s gone. Every new session is a blank slate. Your agent doesn’t remember the customer’s name, their shipping issue from Tuesday, or the workaround your team suggested on Thursday.
Salesforce published a benchmark in 2025 showing that AI agents resolved only 35% of multi-turn customer support tasks end-to-end. The top failure mode? Context loss. The agent literally forgets what the customer said two turns ago.1
That’s the memory problem. And in 2026, it’s the single biggest gap between “impressive demo” and “production-ready agent.”
TL;DR
Agent memory is a notebook your AI keeps between conversations. Without it, every session starts from zero, like talking to a colleague with amnesia every morning.
Memory is what separates a stateless chatbot from a persistent, learning system. The model provides intelligence. Memory provides continuity.
It works in layers: short-term memory holds the current conversation, long-term memory persists across sessions (preferences, facts, past decisions), and the context window is where the model actually reads from. The engineering challenge is deciding what moves between layers.
The counterintuitive insight: bigger context windows don’t solve memory. Stuffing 200K tokens of history into every API call creates unsustainable cost and latency. The real solution is teaching agents to forget intelligently.
The Simple Ancestor: Statefulness
Before we get into agent memory, let’s talk about something every engineer already knows: state.
You’ve built stateful applications your entire career. A shopping cart remembers what you added. A to-do app remembers your tasks between sessions. A database persists information across server restarts. State is the foundation of useful software.
LLMs, by default, have none of it.
Every API call to GPT-4, Claude, or Gemini is stateless. The think-act-observe loop we covered in What is an AI Agent? runs fresh every time. You send a prompt, you get a response, and the model immediately forgets the exchange happened. There’s no session. No history. No continuity. It’s like calling a help desk where the agent hangs up and gets replaced by a new person after every sentence. This is one of the core failure patterns we covered in Why AI Agents Keep Failing in Production.
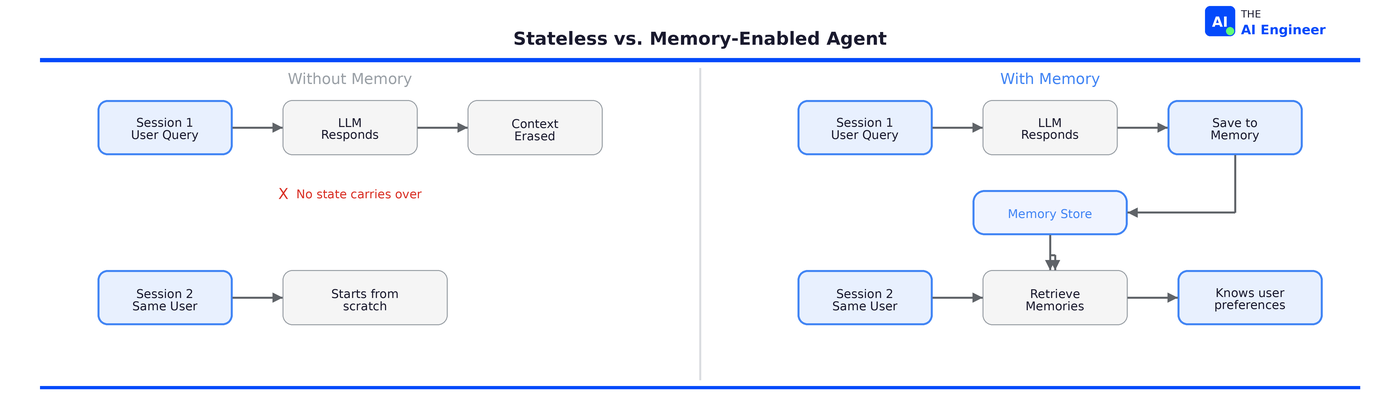
Think of our notebook analogy. The context window is a whiteboard: it holds whatever’s written on it right now, but someone erases it after each session. Agent memory is the notebook in your desk drawer: it persists between sessions, and you pull out only the pages you need for today’s meeting.
That distinction (whiteboard vs. notebook) is the core engineering problem of agent memory.
How It Actually Works
Agent memory operates in three layers. But first, here’s what the problem looks like in code. This is a standard stateless API call:
# Session 1: User tells the agent their preference
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "I prefer dark mode in all my tools."}]
)
# Agent acknowledges: "Got it, I'll remember that!"
# Session 2: New API call. Fresh context. The preference is gone.
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Set up my dev environment."}]
)
# Agent has no idea about dark mode. Starts from scratch.
No state carries over. The “I’ll remember that!” was a lie. The model had no mechanism to actually store or retrieve that preference. This is the default behavior of every LLM API. Now let’s walk through each layer of the fix.
Layer 1: Short-Term Memory (The Whiteboard)
This is the active conversation. The messages exchanged in the current session, the intermediate reasoning steps, the tool calls and their results. It lives inside the context window and gets cleared when the session ends.
Implementation is straightforward: a conversation buffer, usually just an array of message objects. Every agent framework (LangChain, LlamaIndex, CrewAI) includes this out of the box.
The limitation is also straightforward: context windows have a token limit. Even at 200K tokens (Claude) or 2M tokens (Gemini), dumping full conversation history into every call gets expensive fast and degrades model performance. Research shows that model accuracy drops measurably beyond 50K tokens due to attention dilution.2
Layer 2: Long-Term Memory (The Notebook)
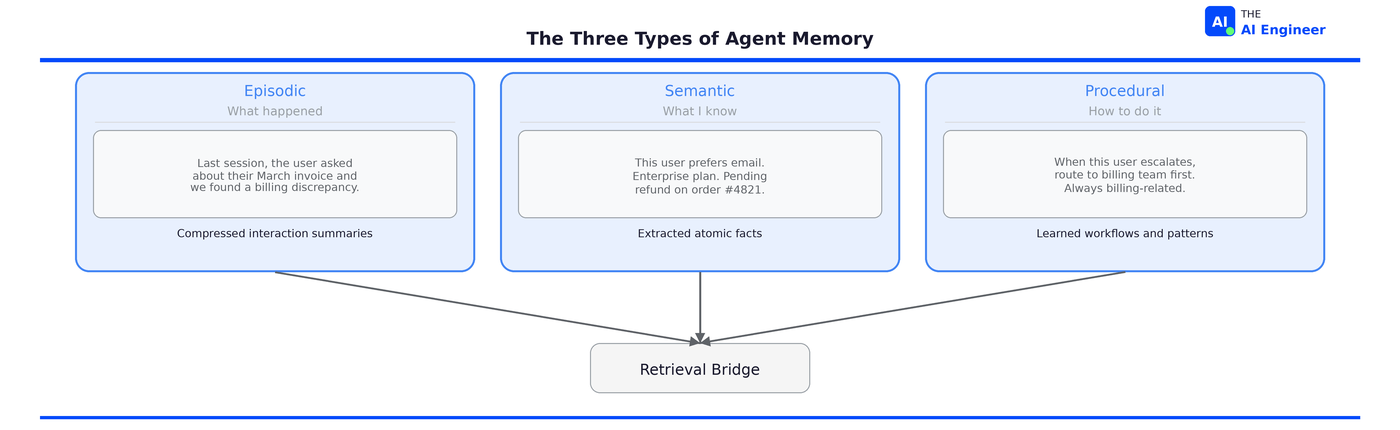
This is where things get interesting for production agents. Long-term memory persists across sessions. It stores three types of information, mirroring how human cognition works:
Episodic memory records what happened. “Last session, the user asked about their March invoice and we found a billing discrepancy.” These are compressed summaries of past interactions, not raw transcripts.
Semantic memory stores facts and knowledge. “This user prefers email over phone. Their account is on the Enterprise plan. They have a pending refund from order #4821.” These are extracted, atomic facts that get updated when new information contradicts them.
Procedural memory captures how to do things. “When this user escalates, route to the billing team first because their issues are always billing-related.” These are learned workflows and patterns.
Here’s a minimal implementation with Mem0, the most widely adopted memory framework right now (48K GitHub stars, chosen by AWS as the exclusive memory provider for their Agent SDK):
from mem0 import Memory
from openai import OpenAI
m = Memory()
client = OpenAI()
# Store a memory after a conversation
m.add(
"User prefers dark mode and uses vim keybindings.",
user_id="alice"
)
# Later, in a new session, retrieve relevant memories
results = m.search("What are Alice's preferences?", user_id="alice")
# Inject memories into the system prompt
memories_text = "\n".join([r["memory"] for r in results])
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": f"You know this about the user:\n{memories_text}"},
{"role": "user", "content": "Set up my new dev environment."}
]
)
# The agent now configures dark mode + vim without asking
That’s the full loop: store after conversations, retrieve before them, inject into context. Behind that simple API, the framework runs an extraction pipeline that converts conversation messages into atomic facts, compares new facts against existing ones, and chooses whether to add, update, merge, or ignore. When a user corrects a preference (”Actually, I switched to VS Code”), it updates the existing memory rather than creating a duplicate.
If you’re mapping out where memory fits alongside RAG, function calling, and the rest of the stack, we built the full roadmap in From Software Engineer to AI Engineer in 2026.
Layer 3: The Retrieval Bridge
Here’s the engineering challenge: the model can only read from its context window (Layer 1). Long-term memory lives outside of it (Layer 2). Something has to decide what memories are relevant to the current conversation, pull them from storage, and inject them into the context window. If this sounds like RAG, it should. The retrieval bridge is RAG applied to conversation history instead of documents.
This is the retrieval bridge, and it’s where the real architectural decisions happen.
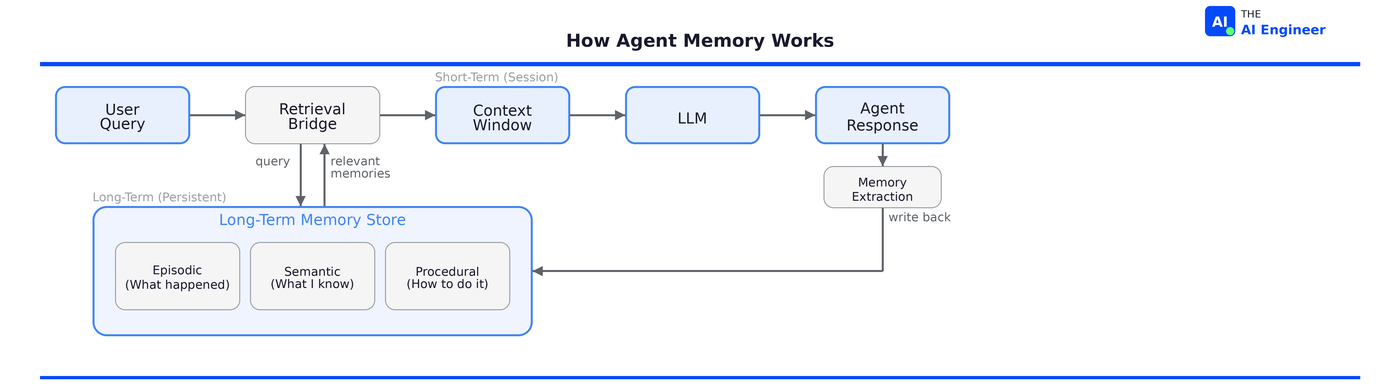
The retrieval bridge typically uses one of three strategies:
Vector similarity search. Embed the current query, find the most semantically similar stored memories. Fast, scales well, and good enough for many use cases. But it has a fundamental blind spot: it can only find memories that are similar to the query, not memories that are logically connected. Ask “What products did this user review that relate to their previous purchase?” and vector search returns the most semantically similar memories, which may not be the right ones. It can’t follow the chain: user → bought laptop → reviewed sleeve → sleeve is for the laptop. This is where most teams start, and where many hit their first production wall.
Knowledge graph traversal. Store memories as entities with typed relationships. “Alice” → “prefers” → “dark mode.” “Alice” → “works at” → “Acme Corp.” → “uses” → “AWS.” Now you can walk the graph: “What cloud provider does Alice’s company use?” requires two hops, and graph traversal handles it naturally. Temporal knowledge graphs go further by tracking when relationships formed and changed, so the agent knows whether “Alice works at Acme Corp” is still true. The tradeoff is infrastructure complexity and higher latency per query.
Hybrid retrieval. Combine vector search, graph traversal, keyword matching (BM25), and temporal filtering. Run all strategies in parallel and use a cross-encoder to rank and merge results. Modern frameworks like Hindsight do exactly this: four retrieval strategies simultaneously, with reranking, and benchmarks showing measurably better accuracy than single-strategy approaches. This is where production systems are heading in 2026, because no single strategy catches everything.
⚠️ Confusion Alert: Context window size and memory are not the same thing. Claude’s 200K token window and Gemini’s 2M token window are working memory, not storage. Injecting full conversation history into every API call costs more, takes longer, and actually degrades model performance beyond certain thresholds. Agent memory is about selective retrieval: pulling in only what’s relevant, not dumping everything.
Who’s Actually Building With This
Let’s ground this in production reality.
ChatGPT and Claude both launched user-facing memory features in 2025, and they took fundamentally different approaches. ChatGPT auto-generates a user profile that’s injected into every conversation: preferences, past topics, personal details. It’s always on. Claude takes the opposite approach: memory is implemented as tool calls that the model chooses when to invoke, searching through raw conversation history on demand rather than maintaining a pre-built dossier. The architectural difference matters. ChatGPT optimizes for passive personalization. Claude optimizes for transparency and user control.
Mem0 has become the default memory layer for the agent ecosystem. API calls grew from 35 million in Q1 2025 to 186 million in Q3. CrewAI, Flowise, and Langflow all integrate Mem0 natively. And the engineering results from their research paper tell the real story: the full-context approach (stuffing everything into the prompt) took 17 seconds per response and consumed 26,000 tokens per conversation. Mem0 cut response time to 1.44 seconds (92% faster) using just 1,764 tokens (93% fewer). That’s the difference between a production system and a demo that burns money.3
Letta takes a different approach entirely: instead of the developer managing memory, the agent manages its own. Letta treats the LLM like an operating system kernel: the agent decides what to promote to core memory, what to archive, and what to forget. It’s the most radical architecture in the space and recently hit #1 on Terminal-Bench (the coding agent benchmark) as a model-agnostic agent. The tradeoff is complexity: Letta requires you to adopt its full agent framework. If you’re already running LangChain or CrewAI, that means migrating your entire agent stack.
Claude Code confronted the memory problem head-on. Long-running coding projects span dozens of sessions. Without memory, the agent would forget what files it had already edited, which approaches it had tried and rejected, and what the user’s code style preferences were. Anthropic’s solution: a structured memory system where an initializer agent sets up the environment, a coding agent makes incremental progress per session, and structured artifacts (progress logs, feature checklists) bridge the gap between sessions. When combined with memory tools, Anthropic reported a 39% performance improvement on agentic search tasks. They recently shipped “Auto Dream,” a feature that consolidates memory files between sessions to prevent the notebook from becoming noise.4
The enterprise picture tells the same story from the other side. Salesforce’s 2025 benchmark found that AI agents resolved only 35% of multi-turn support tasks, primarily because they lose context between turns.5 And Klarna’s AI agent story (which we covered in What is an AI Agent?) is partly a memory story. The agent crushed simple tickets: 2.3 million conversations in its first month. But on complex cases requiring context from previous interactions, customers got generic answers to nuanced problems. Klarna had to rehire human agents. The model was smart enough. The memory wasn’t there.
What Can Go Wrong (and What’s Overhyped)
Let’s be real: agent memory in 2026 is necessary but not solved.
The forgetting problem is a feature, not a bug. Human memory forgets constantly, and that’s adaptive. Agents need to forget too. Stale memories (”user’s shipping address is 123 Oak St” when they moved six months ago) are worse than no memories at all. The engineering challenge is importance scoring and temporal decay: how do you decide what’s worth keeping? Most memory frameworks handle this with a four-operation system (add, update, merge, delete) triggered by an extraction LLM. But it’s still brittle. Production teams report that memory quality degrades over time without active maintenance.
Privacy is a minefield. An agent that remembers everything about your customers also creates a liability. PII in embeddings is hard to audit and harder to delete. GDPR right-to-be-forgotten requests become an engineering nightmare when memories are stored as dense vector representations. Some frameworks offer built-in PII redaction, but most punt on this problem entirely. If you're building for enterprise, memory governance needs to be in your architecture from day one.
Benchmark wars are real and misleading. Mem0 cites strong scores on the LOCOMO benchmark. Hindsight (a newer framework) claims 91.4% accuracy on LongMemEval versus Mem0’s 49.0% on the same benchmark.67 But both benchmarks only measure one thing: fact retrieval from long conversations. They don’t measure whether accumulated memory actually improves task outcomes over time. The benchmarks tell you the retrieval engine works. They don’t tell you whether it makes your agent better at its job.
The “bigger context window” myth. Every few months, a new model ships with a larger context window and someone asks: “Doesn’t this just solve memory?” No. Andrej Karpathy put it well: the context window is RAM. Don’t dump your hard drive into RAM. A 200K-token context window that carries full conversation history across 50 sessions would cost a fortune in API calls and actually hurt model performance. Memory is about selective retrieval, not total recall.
🔎 Deeper Look: The survey paper “Memory in the Age of AI Agents” (December 2025, arXiv 2512.13564) provides the most comprehensive taxonomy of agent memory systems published to date. Key insight: traditional short-term/long-term categories are insufficient. The paper proposes organizing memory by forms (what’s stored), functions (what it enables), and dynamics (how it evolves). Essential reading if you’re designing a memory architecture.
What’s the worst memory failure you’ve seen in a production agent?
Or the most creative workaround?
I want to hear it.
The One Thing to Remember
Agent memory doesn’t make the model smarter. The intelligence was always there.
What memory does is give that intelligence continuity. A model without memory is a brilliant consultant you hire for one hour, who forgets you exist the moment they leave the room. A model with memory is a colleague who builds context over time, learns your preferences, remembers what worked and what didn’t, and gets more useful every week.
🏗️ Engineering Lesson: Memory is infrastructure, not a feature. Just as every application needs a database, every production agent needs a memory layer. And just like databases, the hard problem isn’t storing information. It’s deciding what to store, when to retrieve it, and when to let it go.
Where to Next?
🔭 Go deeper: Single-Agent Patterns (ReAct, CodeAct, Self-Reflection) drops this Thursday. Memory is what agents need to persist. These patterns are how they’re architected.
🧱 Go simpler: What is MCP? explains how agents connect to external tools. Memory explains how they remember what those tools returned.
🔗 Go adjacent: What is Function Calling? explains how agents take actions. Memory explains how they remember what they’ve done.
Salesforce AI Research, CRMArena-Pro: Holistic Assessment of LLM Agents (May 2025).
Chroma, Context Rot: How Increasing Input Tokens Impacts LLM Performance (July 2025).
Mem0, Building Production-Ready AI Agents with Scalable Long-Term Memory (April 2025).
Anthropic, Effective Harnesses for Long-Running Agents (December 2025).
Salesforce, AI Agent Benchmark Study (May 2025).
Hindsight, Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects (December 2025).
Pollertlam & Kornsuwannawit, Beyond the Context Window: A Cost-Performance Analysis of Fact-Based Memory vs. Long-Context LLMs for Persistent Agents evaluation (March 2026).
https://knowledgenetworks.substack.com/p/david-cross-explains-ai-native-thinking?r=7ykchg&utm_campaign=post&utm_medium=web&showWelcomeOnShare=true
Strong framing. I keep seeing teams treat this as a model problem when it is really an operational-memory problem: prior decisions, constraints, docs, transcripts, and email live outside the agent, so humans become the manual context layer.
Curious what you see as the hardest part in practice: remembering, retrieval quality, or trust/provenance? And do teams treat this as urgent enough to budget for, or still more like infra they hack around?