

What Is RAG (Retrieval-Augmented Generation)?
How to stop your LLM from making things up

Air Canada’s customer support chatbot told a grieving passenger he could book a flight at full price and claim a bereavement discount within 90 days. He booked. He flew. He applied for the refund. Air Canada said no: their actual policy requires the discount before booking. The chatbot had confidently quoted a policy the airline had deprecated months earlier.
Air Canada tried to argue the chatbot was basically a separate legal entity responsible for its own mistakes. The tribunal called this “a remarkable submission” and ordered the airline to pay. The chatbot came down from the website shortly after.1
Here’s the thing: this wasn’t a rare edge case. Research shows AI chatbots hallucinate 3% to 27% of the time, even in setups designed to prevent it. And 60% of production AI applications are now powered by systems that answer questions from company data. So how do you build a system that actually checks its sources before opening its mouth?
TL;DR
RAG is an open-book exam for AI. Instead of answering from memory (which is how LLMs hallucinate), the system retrieves relevant documents first, then generates an answer grounded in what it actually found.
It solves the “confident liar” problem. LLMs are trained on static data that goes stale. RAG lets them access your current docs, policies, and knowledge base without retraining the model.
The mechanism in one sentence: User asks a question → system searches a knowledge base for relevant chunks → those chunks get stuffed into the prompt → LLM generates an answer using that context.
Who’s using it: Harvey AI (legal research), Shopify (merchant support), and roughly 60% of all production AI applications as of 2025.
The counterintuitive part: The retrieval matters more than the generation. What makes or breaks it is the retrieval: how you chunk your docs, how you search them, and whether the right context actually lands in the prompt.
Let’s get into it.
Before RAG, There Was “Just Ask the Model”
Think of an LLM like a brilliant colleague who read the entire internet... two years ago. They can discuss almost anything with impressive fluency. But ask them about your company’s current refund policy, last quarter’s pricing changes, or the API docs you updated on Thursday? They’ll either admit they don’t know (best case) or, more dangerously, they’ll make something up that sounds right.
This is the fundamental limitation of relying purely on a model’s parametric knowledge (the stuff baked into its weights during training). The model’s knowledge is frozen at its training cutoff. It has no idea what’s in your internal docs. And it can’t tell you where it got its answer from, because it didn’t “get” it from anywhere. It generated it from statistical patterns.
For a while, the answer was: just stuff everything into the prompt. Got 50 pages of documentation? Paste it all in as context. This worked for small datasets, but it hits walls fast. Context windows have limits, costs scale linearly with token count, and dumping irrelevant information into the prompt actually degrades answer quality. You’re paying more for worse answers.
⚠️ Confusion Alert: “But context windows are huge now, can’t I just throw everything in?” This is the most common objection in 2026, and it’s partially valid. Models like Gemini support 1M+ tokens. But long-context models still struggle with the “needle in a haystack” problem at scale, they’re expensive to run on every query, and they can’t tell you which document their answer came from. RAG and long context aren’t competitors. They’re complementary. More on this in the tradeoffs section.
Why “Just Ask the Model” Breaks Down
Let’s go back to Air Canada. Imagine you’re the engineer who built that chatbot. Your approach: take a powerful LLM, maybe add a system prompt that says “You are Air Canada’s customer support assistant. Be helpful and accurate.”
Here’s what goes wrong:
Problem 1: Stale knowledge. Air Canada changed their bereavement policy. The model was trained (or fine-tuned) on the old version. It doesn’t know the policy changed. It answers confidently with outdated information. The customer relies on it. You lose a tribunal case and a chatbot.
Problem 2: No source attribution. When the customer asks “can I apply for a bereavement fare retroactively?”, the model generates a fluent answer. But there’s no way to verify where that answer came from. Was it the current policy doc? The old one? A blog post from a travel forum? A pattern it learned from training data? You literally cannot tell.
Problem 3: Hallucination under uncertainty. When the model doesn’t have enough information, it doesn’t say “I don’t know.” It interpolates. It generates plausible-sounding text that fills the gap. Stanford research found that even specialized legal AI tools produce incorrect information 17–34% of the time. General-purpose models hallucinate on legal queries up to 82%.2
Problem 4: No updates without retraining. Every time you change a policy, update docs, or add a new product, the model doesn’t know until you retrain or fine-tune. That’s expensive, slow, and often impractical for rapidly changing information.
Problem 5: Cost at scale. Stuffing all your documentation into every prompt is wildly expensive. If your knowledge base is 100,000 documents, you need a smarter way to find the 3–5 relevant ones for each specific question.
By now, the need should be obvious: what if the model could look things up before answering?
How RAG Actually Works
Retrieval-Augmented Generation exists because of every problem listed above. The concept is simple: before the model answers anything, the system searches your knowledge base for relevant documents and stuffs them into the prompt. The model reads the evidence first, then responds.
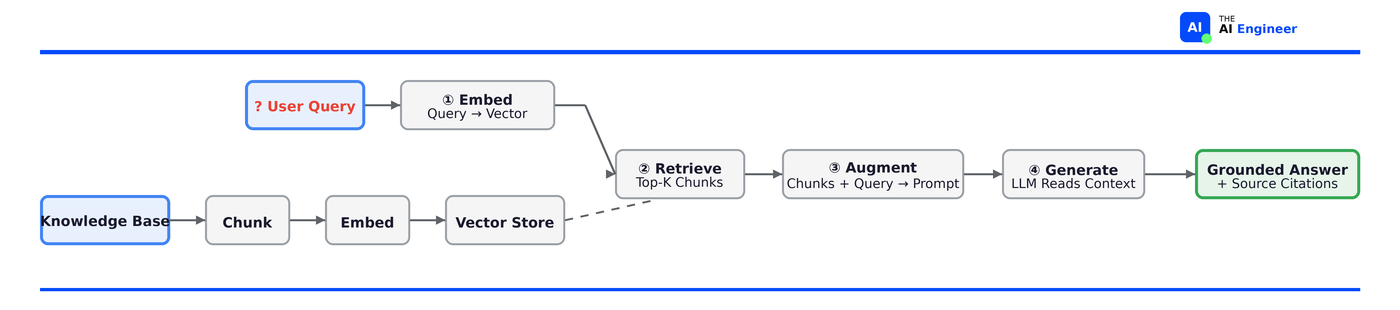
Let’s walk through each step, using the Air Canada scenario as our running example.
Embed the query. The user asks: “Can I apply for a bereavement fare after I’ve already booked my flight?” This natural language question gets converted into a vector: a list of numbers that captures the question’s meaning. An embedding model handles this conversion. Two questions with completely different wording but the same intent (”Can I get a refund after booking?” and “Is retroactive reimbursement possible?”) end up as nearly identical vectors. That’s what makes the next step work. In our open-book exam analogy: this step is the student reading the question and understanding what they need to look up.
Retrieve relevant chunks. That query vector gets compared against all the document chunks in your vector store (your indexed knowledge base). The system finds the top-K most semantically similar chunks. In our case, it would pull up the current bereavement policy document, the FAQ about fare types, and maybe the terms of service section on refunds. This step is the student flipping to the relevant pages in their textbook. They’re not reading the whole book, just the parts that match what the question is asking about.
Augment the prompt. The retrieved chunks get assembled alongside the original question into a single prompt. Something like:
Based on the following context, answer the user's question.
Context:
[Bereavement policy doc, last updated January 2026]
"Bereavement fares must be requested PRIOR to ticket purchase.
Retroactive applications are not accepted..."
[FAQ: Fare types]
"Bereavement fares are available for immediate family members.
Documentation required within 14 days of travel..."
Question: Can I apply for a bereavement fare after I've already
booked my flight?
This is the student writing their answer with the textbook open in front of them.
Generate a grounded answer. The LLM receives this augmented prompt and generates an answer. But now, critically, it has the actual, current policy right there in context. The answer: “No, Air Canada’s bereavement fares must be requested before purchasing your ticket. Retroactive applications are not accepted.” The answer returns with citations. A well-built RAG system can tell the user which documents the answer came from, with links. This is the open-book exam equivalent of showing your work.
The key insight: the LLM’s job in a RAG system isn’t to know the answer. It’s to read the answer from the right documents and present it clearly. The retriever does the sourcing. The generator does the communicating.
🔍 Deeper Look: The
pguso/rag-from-scratchGitHub repo walks through building the entire pipeline step-by-step without frameworks. Great for understanding what’s actually happening under the hood before reaching for LangChain or LlamaIndex. [github.com/pguso/rag-from-scratch]
Who’s Actually Building With This
Harvey AI built its entire legal research platform on RAG, and then discovered where RAG runs out of road. Their system handles three tiers of data: documents uploaded per conversation (1–50 files), long-term project vaults (1,000–10,000 documents), and third-party legal databases covering case law, statutes, and regulations across 45 countries. The result: their Tax AI Assistant, built with PwC’s tax professionals, is preferred over off-the-shelf ChatGPT 91% of the time. But Harvey’s co-founder put the limitation bluntly: basic retrieval can answer simple questions about areas of law, but real case law research requires finding ammunition for an argument, and that’s a fundamentally harder problem. Harvey ended up layering custom-trained models on top of RAG to get there.3 That’s worth remembering: RAG is the foundation, not the ceiling.
Shopify powers its merchant assistant Sidekick with RAG, pulling from help docs, store data, and product catalogs so merchants can ask plain-language questions like “which of my customers are from Toronto?” and get answers grounded in their actual store. The engineering lesson that matters here: as they scaled Sidekick’s capabilities, they found that stuffing every tool instruction into the system prompt degraded performance across the board. Their fix was Just-in-Time instructions, loading only the relevant context for each specific task into the prompt. Same principle as RAG itself: give the model exactly what it needs, nothing more.4
Hugging Face ran a benchmark that should make every RAG engineer pause. Testing 156 queries against nuclear engineering documents, they found that “best practices” often failed on their specific data. Naive chunking outperformed context-aware chunking (70.5% vs 63.8%). Chunk size barely mattered. Hybrid retrieval lost to dense-only retrieval.5 Their takeaway: don’t blindly follow best practices. Benchmark on YOUR document types. The defaults might be actively making your system worse.
What Can Go Wrong (and What’s Overhyped)
RAG is genuinely useful. It’s also genuinely imperfect. Here’s what breaks:
Garbage in, garbage out, but harder to detect. If your knowledge base contains outdated, contradictory, or poorly written documents, RAG will faithfully retrieve and cite them. The system doesn’t evaluate whether a document is correct, only whether it’s relevant. Air Canada’s chatbot likely retrieved an old version of the bereavement policy. The retrieval worked perfectly. The knowledge base was the problem.
Chunking is an unsolved art. How you split documents into chunks dramatically affects retrieval quality, and there’s no universal answer. Split too small and you lose context. Split too large and you dilute relevance. Split at the wrong boundaries and you break the meaning of a paragraph. Hugging Face’s nuclear engineering benchmark proved that the “right” chunking strategy is domain-dependent and often counterintuitive. We’ll compare chunking approaches in a future Thursday issue: fixed vs semantic vs agentic chunking.
The “lost in the middle” problem. Research shows LLMs pay more attention to information at the beginning and end of their context window, partially ignoring what’s in the middle. If your critical chunk lands in position 4 of 8 retrieved documents, the model might underweight it. Retrieval order matters more than most teams realize.
Evaluation is still largely vibes. As of 2025, 70% of RAG systems lack systematic evaluation frameworks. Teams ship improvements and hope things got better. Tools like RAGAS and Braintrust are starting to solve this, but the field is immature. If you can’t measure retrieval quality, you can’t improve it.
The honest hype check. The “RAG is dead” takes circulating in early 2026 are mostly clickbait, driven by the expansion of context windows to 1M+ tokens. Yes, long-context models reduce the need for RAG on small knowledge bases. But for production systems with thousands of documents, rapidly changing data, cost-sensitive deployments, and auditability requirements RAG isn’t going anywhere. It’s evolving toward agentic RAG, GraphRAG, and hybrid retrieval, but the core pattern of “look it up before you answer” is fundamental.
🏗️ Engineering Lesson: RAG and memory are not the same thing. RAG retrieves documents at query time. Memory means an agent that remembers your preferences across sessions, learns from past interactions, and updates its own understanding. One is search. The other is state. If you need both, RAG is the foundation but not the full answer. We’ll cover agent memory in a future issue.
The One Thing to Remember
RAG doesn’t make the model smarter. It doesn’t give it new capabilities or better reasoning. What RAG does is change the model’s information diet: from “everything I memorized during training” to “the specific documents that are actually relevant to this question, right now.” The model is the same. The input is radically different. And that difference is the gap between a chatbot that costs you a lawsuit and one that earns customer trust.
Where to Next?
📖 Go deeper → Thursday Issue #6: The AI Agents Stack (2026 Edition). Where does RAG fit in the full agent architecture? The memory layer, mapped. [Thursday Deep Dive]
🔗 Go simpler → Issue #9: What Are Embeddings? The vector math that makes semantic search possible, explained without the math anxiety. [101 Explainer]
🔀 Go adjacent → Issue #7: What is Fine-tuning? When paying OpenAI $0.03/call stops making sense. [101 Explainer]
What's your RAG setup? Naive chunking that works, or an over-engineered pipeline that doesn't? And if you've hit the retrieval quality wall, what fixed it? Leave a comment below.
Moffatt v. Air Canada, 2024 BCCRT 149. The tribunal’s ruling generated international headlines. As of April 2024, Air Canada’s chatbot is no longer available on their website.
Stanford HAI, “Do Large Language Models Produce Adequate Legal Analyses?” (2024). Tested leading legal AI tools on real case law.
Harvey AI engineering blog, "Enterprise-Grade RAG Systems" (2025); OpenAI case study, "Customizing Models for Legal Professionals" (2024). Harvey serves 97% of Am Law 100 firms across 45 countries.
Shopify Engineering, "Building Production-Ready Agentic Systems: Lessons from Shopify Sidekick" (2025). Presented at ICML 2025.
Hugging Face, "Benchmarking RAG on Nuclear Engineering Documents" (2025). 156 queries, 8 chunking strategies, 4 retrieval methods tested.