

How CodeRabbit Actually Works
Inside the agentic pipeline behind 10M+ code review

It is 2am and the on-call phone is going off. Checkout is throwing null-pointer errors, and the trace points to a PR that merged yesterday with two approvals and a green check. The diff looked harmless: a small refactor to a payment helper. Both reviewers missed it because it lived three files from the diff: the refactor changed a return type that a downstream caller still depended on. Nobody opened that file. Why would they? It was not in the diff. The review was fast, friendly, and wrong, and it shipped two thumbs-up straight into production.
A careful senior engineer would have caught it by opening the downstream file, checking the call sites, and running the tests. That gap, between what a diff shows and what a change reaches into, is the whole problem CodeRabbit set out to solve. It automates the part of review that has nothing to do with writing comments: tracing what a change actually touches.
TL;DR
CodeRabbit is an AI code reviewer that works a pull request the way a thorough senior engineer would.
It exists because reviewers skim, and the expensive bugs hide in the files the diff does not show.
The scale is real: 100,000+ daily users, 8,000+ paying customers, $15M+ ARR, a $60M Series B at a $550M valuation (Sept 2025), the most-installed AI app on GitHub and GitLab.
The review agent investigates by writing shell commands in a sandbox (cat, grep, ast-grep) rather than calling predefined tools, so there are no tool schemas to maintain.
📣 Sponsored by

They had no say in what this teardown concludes, same depth and honesty as every issue. What they did do: hand you $50 free credit to try out the tool.
Why One Model Pass Falls Short
CodeRabbit sells itself as an “AI code reviewer,” which suggests a model reading your diff and leaving comments. That model is real, but is the least interesting part. Most of the work happens before it: cloning the repo, mapping what the change touches, running linters, reading CI logs, and pulling the team’s past review preferences. CodeRabbit’s co-founder and CEO, Harjot Gill, put it plainly: “It’s not like the agentic loop that everyone else has. It’s a pipeline in a way, and a lot of the work goes into preparing the context.”
⚠️ Confusion Alert: “Agentic code review” sounds like a model roaming your codebase with no guardrails. The full version of agent autonomy, covered in What is an AI Agent?, is a system that plans and acts on its own; what CodeRabbit runs is a scoped version of that, with the agent free to investigate only inside fixed pipeline stages. That scoping is what keeps the output trustworthy.
The Architecture
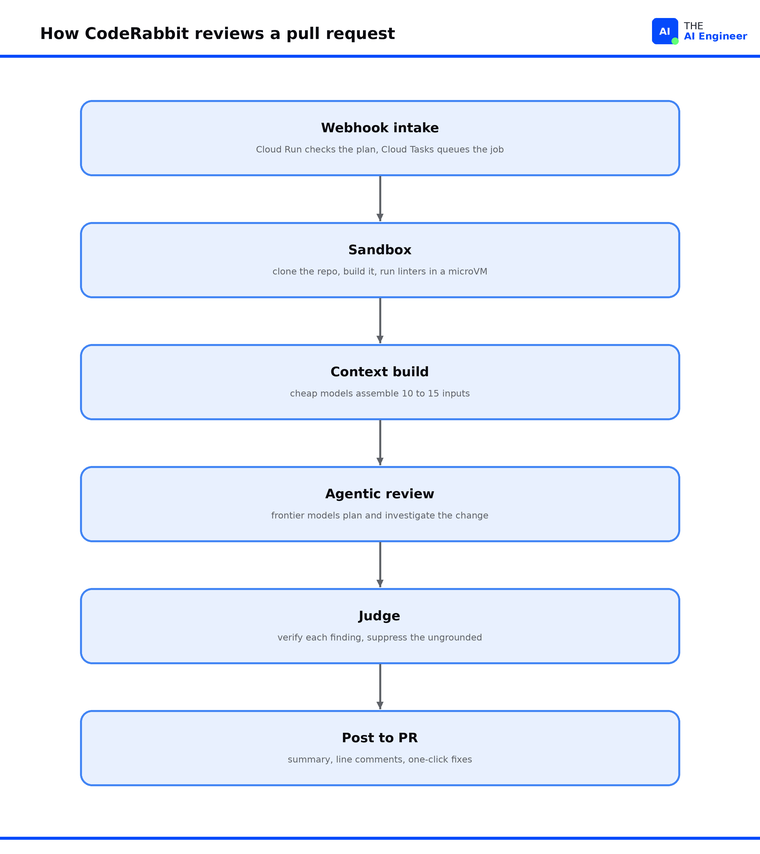
The pipeline runs five jobs on every PR. Here is each one, in order.
Webhook and queue. A PR opens on GitHub, GitLab, Azure DevOps, or Bitbucket. The webhook hits a small Cloud Run service, which checks the subscription and drops the job on a Google Cloud Tasks queue1. From there, workers pull jobs one at a time. That queue is what absorbs bursts: when a team pushes a wave of PRs at once, they line up instead of swamping the workers. At peak, CodeRabbit handles up to 10 review requests per second across 200+ Cloud Run instances.
Sandbox. A separate service pulls the job and clones the repo into an isolated microVM, a throwaway machine that exists only for this review. The instance is sized for real work: a one-hour timeout, 8 vCPUs, 32 GiB of RAM, and the repo held in memory. Inside it, CodeRabbit builds the project and runs more than 20 linters and static-analysis tools at once2. The repo is untrusted code from an outside contributor, so the isolation runs two layers deep: the microVM, plus Jailkit-confined processes.
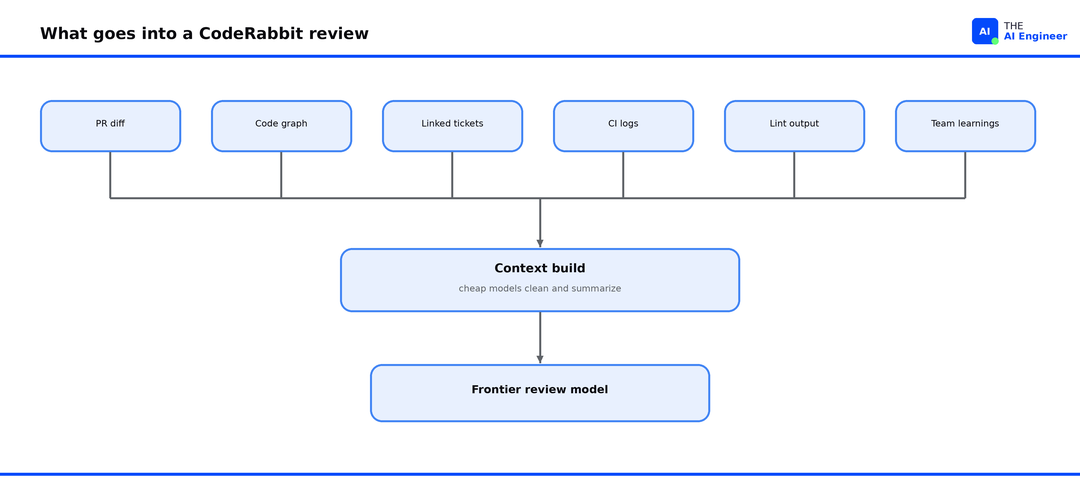
Context build. This stage sets review quality, and it is where most of the compute goes. CodeRabbit assembles 10 to 15 different data points for the change: the diff, a code graph mapping how the edited code connects to the rest of the repo, linked Jira and Linear tickets, CI failure logs, lint output, and the team’s accumulated review preferences. Each input is too large or noisy to pass raw, so cheap models (GPT-4.1 nano and mini) compress them first: a 4,000-line file becomes the few functions the change touches, a long ticket thread becomes its one requirement, verbose logs become the failing lines. The frontier model receives that brief.
Agentic review. A frontier reasoning model then works that brief. This is the investigative core of the system, where the model decides what to examine and how deep to go, and the next section breaks it down3.
Judge and post. Before anything reaches the PR, a separate judge model scores each finding against the gathered context and drops the ones it cannot ground, which is how CodeRabbit holds down false positives. What survives posts as a plain-language summary, inline comments on the exact lines, one-click fixes, and an analysis trail showing the commands behind each finding.
Here is what the context-build step pulls together before the model runs:
The whole process takes one to five minutes before the first comment, sometimes longer server-side. Slow on purpose. The review runs in CI, no one waits at a chat box, and the extra passes result in lower noise4.
Inside the Loop
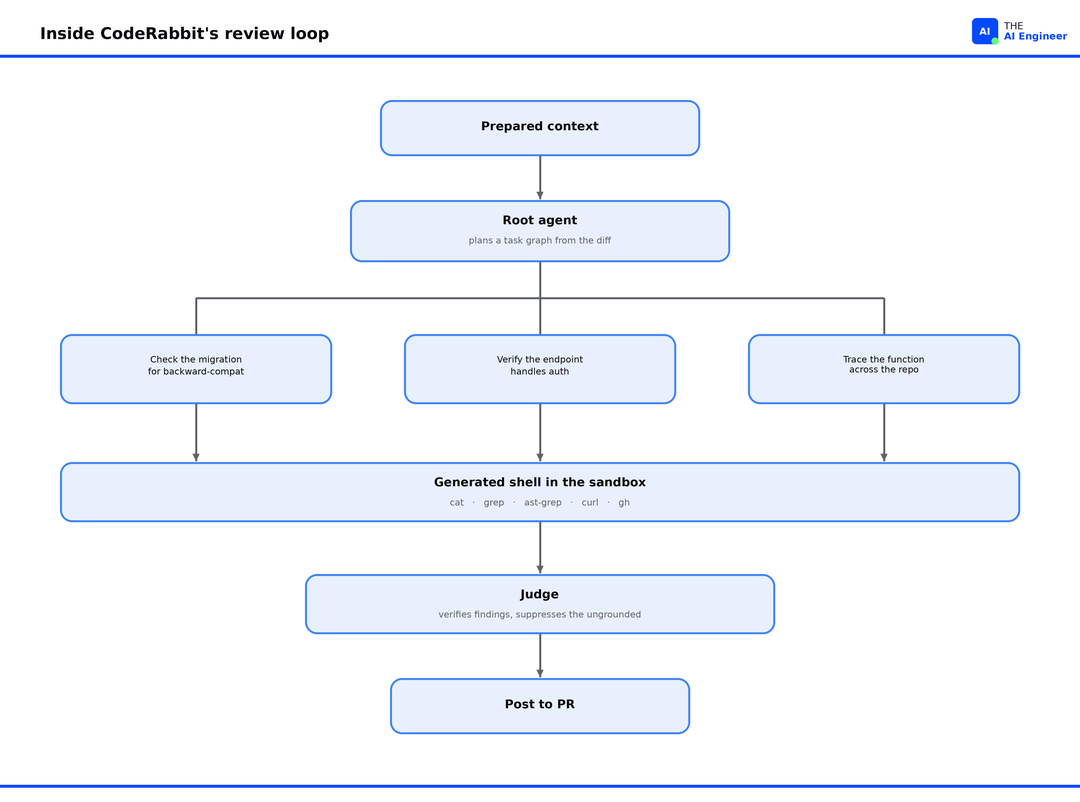
The loop works in two moves, plan then delegate. A planning model reads the prepared context and breaks the review into a task graph: a set of specific jobs the change calls for, like checking the migration for backward compatibility, confirming the new endpoint handles auth, or tracing where the changed function is used. The planner builds that set from what the diff touches, so it differs for every PR. Each job is then handed off and investigated on its own, while the surrounding stages (the clone, the build, the lint run) stay fixed.
To investigate, the agent does not call predefined tools. It writes shell scripts and runs them in the sandbox: cat a file, grep for a pattern, ast-grep for a syntax-aware query, curl to a vulnerability database, the GitHub CLI to open an issue. No tool schemas, no MCP5.
The agent can also look past the diff. It reads the last couple thousand commits through the code graph, runs the tests against the change, and searches the web to confirm a new library or syntax exists, since the model’s training has a cutoff. To keep it from investigating forever, recursion is capped at a fixed depth, and the judge model verifies findings before anything posts. A grep that returns nothing is not proof of a bug; it usually means the agent looked in the wrong place, and the judge filters that out.
The Key Decisions

Generated CLI over tool calls. Most agent frameworks hand the model a set of tools with schemas, an approach called function calling, or wire it up over MCP. CodeRabbit skips both and has the model write bash. The trade: you give up the structure of typed tool calls, and in return you get a model that already writes shell fluently, because shell is everywhere in its training data in a way your custom tool schemas never are. Adding a new capability then means installing a CLI in the sandbox image rather than defining a new tool schema. The catch: this works only in domains the model has seen well (filesystem, git, unix), and only if you can safely run code it writes.
A live code graph over pre-indexed RAG. The obvious approach to repo context is to chunk the code, embed it, and retrieve by similarity. CodeRabbit builds a fresh structural graph of the repo per review instead. A pre-built index goes stale the moment the repo moves, and similarity search surfaces code that looks like the change while missing the code that structurally depends on it. The graph knows that changing a function means visiting its call sites in other files, even when those files share no keywords. CodeRabbit still keeps a vector store (LanceDB) for cross-PR memory, where queries are natural language over past reviews.
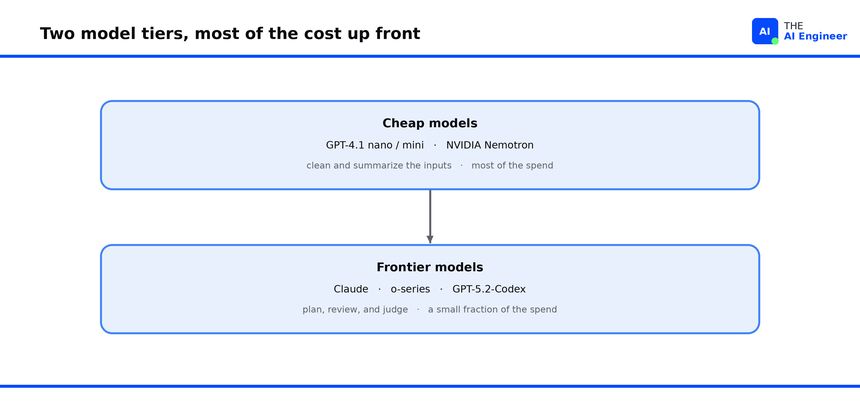
A model ensemble nobody sees. CodeRabbit runs seven or eight models per review and hides which is which. Cheap models do context cleanup, frontier reasoning models do the deep pass, and a judge model verifies. The point is cost discipline. A frontier reasoning model can cost five times a mid-tier one, and orders of magnitude more than a cleanup model. Routing each subtask to the cheapest model that can handle it is what keeps flat per-seat pricing viable. This works only with an evaluation infrastructure good enough to know which model wins each task, which CodeRabbit built in-house.
Who Should Use It
CodeRabbit fits teams with a high PR volume and a codebase where changes routinely reach across files. If your PRs touch code with non-obvious downstream effects, the code graph is what catches the cross-file breakage humans miss. Groupon’s engineering team reported review-to-production time dropping from 86 hours to 39 minutes after adoption. Teams shipping AI-generated code benefit most. CodeRabbit’s own analysis of 470 open-source PRs found AI-co-authored changes carried about 1.7 times more issues than human-only ones6.
It also fits teams that already live in pull requests. CodeRabbit comments where the review already happens, so adoption is close to free. No one has to open a new tool or change how they work.
Who Shouldn’t
If you need synchronous review, the kind that keeps pace with pair programming, the one-to-five-minute latency rules it out. CodeRabbit runs in CI after you open the PR; for live, type-and-see feedback in the editor, it is the wrong tool.
Compliance teams that must know which model touched their code hit a wall, since you cannot pick the model or audit which one wrote a given comment. The hidden ensemble that makes the economics work also makes the provenance opaque.
Teams with low tolerance for noise should go in clear-eyed. An independent audit by the Lychee project of 28 reviewed PRs (32,784 lines across 693 files) classified the comments as 35% genuine quality improvements, 21% nitpicks, 15% useless, and the rest split between thoughtful notes and wrong assumptions. Better than no review, and short of a senior engineer who knows the codebase cold.
My Honest Take
Let me be straight about what is and is not hard here. Most of CodeRabbit’s engineering is portable. Managed serverless and a task queue are commodity infrastructure, and generating shell in a sandbox is a weekend prototype. What does not transfer is the expensive part: the eval harness that knows which of eight models fits each subtask, the language tooling to build a code graph for every language you support, and the volume of real-world feedback it takes to tune the judge so it cuts noise without hiding real bugs7.
The overhyped piece is the autonomy. CodeRabbit looks like a free-roaming AI agent, but what makes it reliable is how tightly it is constrained: fixed pipeline stages, bounded recursion, and a judge gating every finding. Those same constraints target the failure modes catalogued in Why AI Agents Keep Failing in Production. The agent earns trust by staying on a short leash.
💬 Generated shell in a sandbox, or typed tool calls and MCP? If you have built an agent, which did you choose, and why? Tell me in the comments.
Where to Next?
📖 Go Deeper: The AI Agents Stack. The full set of components an agent is built from, the machinery behind the one in this issue.
🔗 Go Simpler: What is an AI Agent?. Start here if task graphs and agent loops are new.
🔀 Go Adjacent: How Cursor Actually Works. The same investigation, aimed at writing code instead of reviewing it.
🗺️ If you are transitioning into AI engineering, How to Break Into AI Engineering in 2026 is the full roadmap on getting there.

🔜 Tuesday: Which NVIDIA GPU Do You Actually Need? How to match the GPU to your workload without overpaying.
How CodeRabbit built its AI code review agent with Google Cloud Run, Google Cloud (Apr, 2025)
What it really takes to bring a new model online at CodeRabbit, Coderabbit (Dec, 2025)
How CodeRabbit’s agentic code validation helps with code reviews, Coderabbit (Nov, 2025)
Our new report: AI code creates 1.7x more problems, Coderabbit (Dec, 2025)
You can build an AI code reviewer. But you probably can’t maintain it, Coderabbit (Jun, 2026)
What makes this work is hiding in the diagram: every step lands in a sandbox, and the output is a review, not a merge. The agent does real work, but a human still presses the button, and the worst case is a comment you ignore. That is the most forgiving place an acting agent can live. The harder question is what this same loop looks like when there is no merge button in front of it, when the action lands in the world the moment the agent decides. The sandbox is doing a lot of quiet work here.