

The AI Agents Stack (2026 Edition)
Six layers between your LLM and a production agent.

Your team picks LangGraph for a customer support chatbot. Three weeks in, you’ve got 14 nodes in a state graph, a custom checkpointer writing to Redis, and retry logic for tool calls that fail once a week. The agent answers refund questions. It calls one API. A 50-line script on the OpenAI SDK with two MCP servers would have done the same thing. But nobody mapped which layers the problem actually needed.
In November 2024, Letta published an AI agents stack diagram that became the default reference for half the engineering teams I talk to1. If you’ve seen a “layers of an agent” visual on LinkedIn or pinned in a Slack channel, it probably traces back to that article.
That diagram is fourteen months old now, and a lot has changed since. MCP didn’t exist yet. Memory was still treated as a subset of your vector database. Nobody was shipping provider-native agent SDKs. Eval wasn’t even on the map. The stack has six layers in 2026, and at least three of them didn’t exist as distinct categories when Letta drew the original.
So we drew it from scratch This is the 2026 version.
TL;DR
That’s the starting stack. Add complexity when something specific breaks, not before.
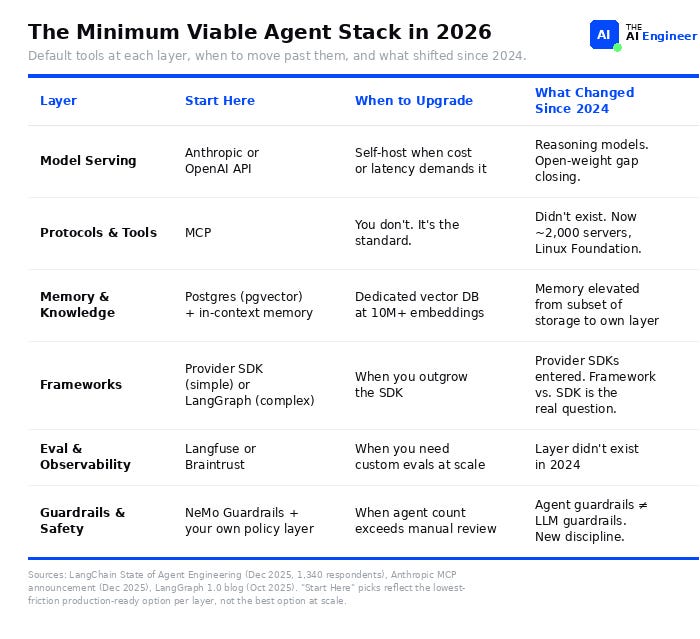
What Are We Even Mapping?
Before the stack, there was a loop. In Issue #1, we defined an agent as the think-act-observe cycle: the model reasons about a task, takes an action (calls a tool, writes to memory), observes the result, and loops until the task is done. That loop is the atomic unit. Everything in this issue is infrastructure that makes that loop work reliably, at scale, in production.
The agent stack is not the LLM stack. A chatbot needs inference and maybe RAG. An agent needs state management across multi-step execution, tool access governed by protocols, memory that persists across sessions, autonomous reasoning loops, and guardrails that constrain behavior in real time. That’s a fundamentally different set of infrastructure problems.
Scope: We’re mapping the 6 layers between your LLM and a production agent. We’re NOT covering training infrastructure, data pipelines, or model fine-tuning. Those are adjacent stacks. We covered RAG in depth in Issue #5. Today we zoom out to show where RAG fits in the bigger picture.
Three things redrew the map between 2024 and 2026. MCP standardized tool connectivity (the entire tools layer is new). Reasoning models changed what agents can do autonomously (single-call agents replaced some multi-step chains). And memory became a first-class architectural primitive, not an afterthought bolted onto a vector database.
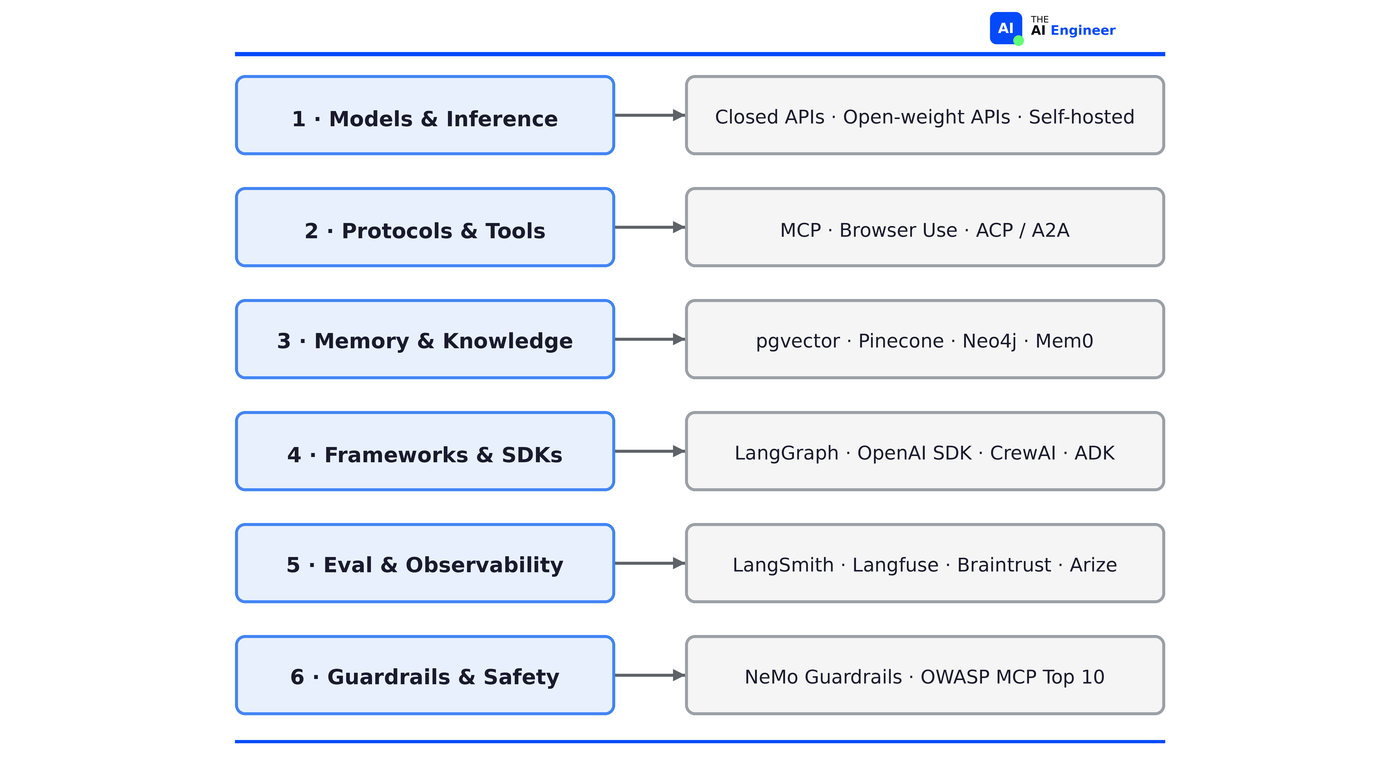
Evaluation framework
When choosing tools at each layer, ask three questions:
How much state do you need to manage? A stateless tool caller and a multi-session agent that learns over time are different engineering problems. The layers where state management is hardest (memory, frameworks) are where most teams get stuck.
How much vendor lock-in can you tolerate? MCP is an open standard. Provider SDKs are not. Every tool choice either increases or decreases how painful your next migration will be.
How hard is it to go from demo to production? Some layers (model serving) have almost no gap. Others (eval, guardrails) have a massive one. The layer where you feel that gap most is the one to invest in first.
We take each layer from the bottom up, starting with the most stable and ending with the least mature. Every layer includes three sections: what changed since 2024, an honest take on the current state, and an evaluation framework that scores state management complexity, vendor lock-in risk, and the gap between demo and production. At the end, a cheat sheet puts all six layers side by side.
Layer 1: Models & Inference
In one sentence: How you run the model that powers your agent: call an API, use a managed open-weight provider, or self-host.

What changed since 2024:
Reasoning models (o1, o3, DeepSeek R1, Claude with extended thinking) shifted what agents can plan and execute. Agents that previously needed multi-step chains can now solve problems in a single reasoning call.
Open-weight models (Llama 3.3, DeepSeek V3, Qwen 2.5) closed the quality gap dramatically. “Always use the biggest closed model” is no longer default advice.
“Prototype on closed-source, deploy on open-weight” is becoming the standard pattern.
🔥 The honest take: This layer is commoditizing. Model differences matter less each quarter. The real decision is cost and latency tradeoff, not which model is “smartest.”
Evaluation Framework:
State management: API calls are stateless. Send a request, get a response. Nothing to manage.
Lock-in risk: high for closed APIs (each model reasons differently, so switching providers means retuning prompts, adjusting for different failure modes, and retesting your eval suite), low for open-weight (swap the model, keep the infra).
Prototype-to-production gap: smallest of any layer. Your demo API call is the same as your production API call.
Takeaway: Self-host when your agent call volume makes API pricing untenable, or when you need sub-100ms latency that API round-trips can’t deliver.
Layer 2: Protocols & Tools
In one sentence: How your agent calls external tools and APIs: through MCP servers, browser automation, or agent-to-agent protocols.

This is what twelve months of MCP adoption did to the tools layer:
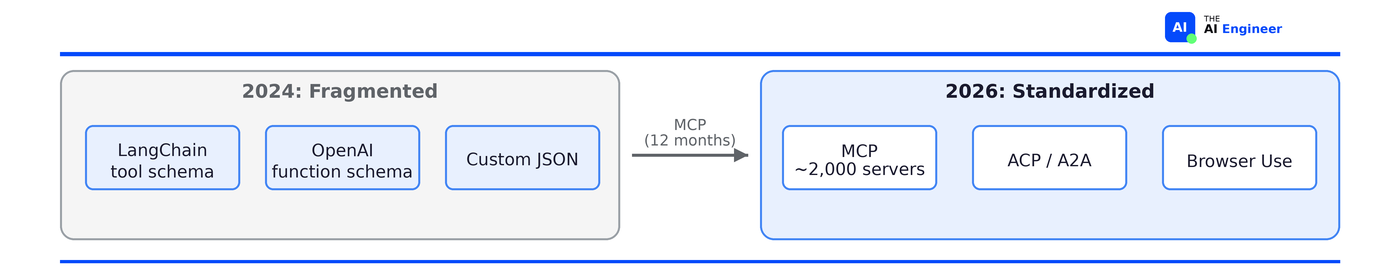
What changed since 2024:
This layer didn’t exist as a distinct category. Every framework had its own JSON schema for tool definitions.
MCP is the standard. 97M monthly SDK downloads. Adopted by OpenAI, Google, Microsoft. Donated to the Linux Foundation.2
Browser Use exploded. Browser Use hit 78K GitHub stars in under a year. Nobody was shipping browser agents in production in 2024.3
Agents can now talk to other agents. IBM launched ACP, Google launched A2A. Neither is standard yet, but the problem they solve (agents coordinating with other agents) is real and growing.
Security is the open problem. Invariant Labs built MCPTox, a benchmark that tests whether malicious MCP servers can hijack agent behavior. Result: 84.2% tool poisoning success rate when auto-approval was enabled.4 Endor Labs analyzed 2,614 MCP servers and found 82% prone to path traversal, 67% to code injection.5
🔥 The honest take:The protocol debate is over. MCP won. The only question left is how you lock down your MCP servers before someone exploits them.
Evaluation framework:
State management: nothing to manage. Your agent calls a tool, gets a response, done. No session, no memory between calls.
Lock-in risk: low. MCP is an open standard. If you build MCP servers, any MCP-compatible agent can use them.
Prototype-to-production gap: medium. Your demo MCP server works until someone sends a malicious tool description. Security and governance are the gap.
🎯 Takeaway: MCP standardized how agents use tools. It says nothing about how agents talk to each other. ACP and A2A are trying to solve that, but neither has reached critical mass. If you need multi-agent coordination today, you're building it yourself at the framework layer. We covered MCP in depth in Issue #4.
Layer 3: Memory & Knowledge
In one sentence: How your agent stores and retrieves what it knows: in-context state, vector search, or persistent memory across sessions.

All three tiers feed into the same place: the context window your agent sees on every call.
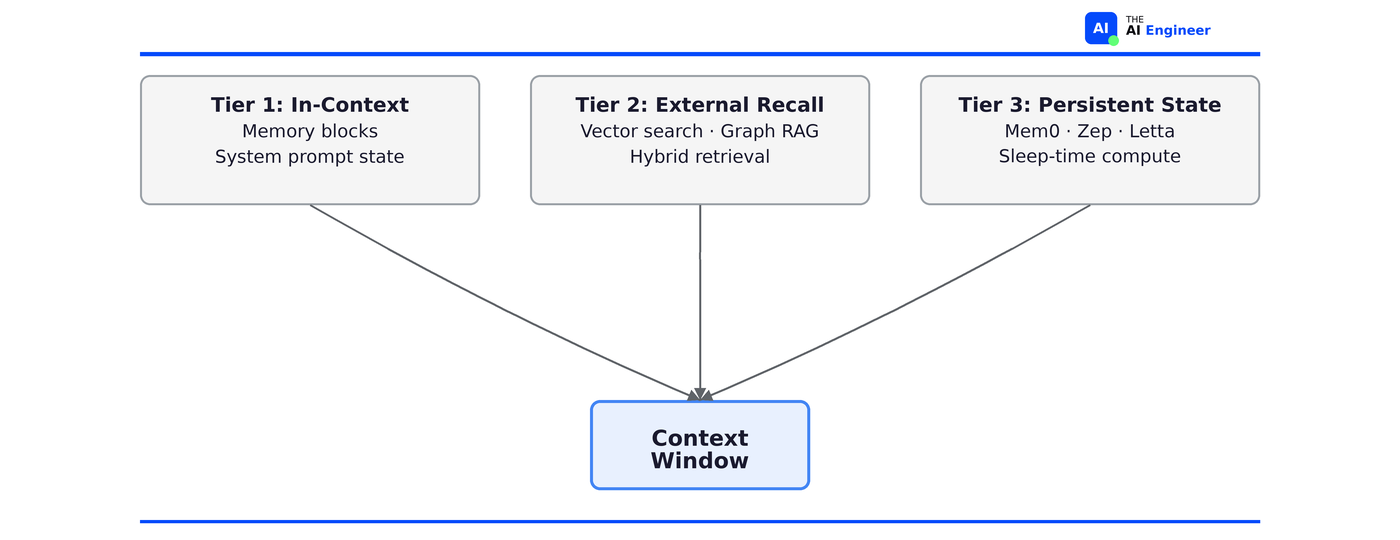
What changed since 2024:
In 2024, memory meant “pick a vector database and do RAG.” In 2026, memory is a first-class architectural primitive with three distinct tiers.
Context windows got massive. Gemini hit 1M+ tokens, Claude 200K. Bigger windows didn’t kill the need for memory. They changed the tradeoff: what do you stuff in-context vs. what do you retrieve on demand?
“Context engineering” replaced “prompt engineering” as the core discipline. Instead of writing a better prompt, you architect what information the agent sees on every call.6
Memory blocks appeared. Named, structured fields in the context window that the agent can read and overwrite every turn. Instead of dumping everything into the system prompt, the agent manages its own state: what to keep, what to update, what to drop.
pgvector became the default for teams that don’t need a dedicated vector database. It’s just Postgres with an extension.
Graph RAG emerged. In 2024, retrieval meant vector similarity search. Graph RAG added a second option: follow relationships between entities instead of matching embeddings. Neo4j is leading this.
Sleep-time compute (agents processing information during idle time) is research-stage but signals where Tier 3 is heading.
🔥 The honest take: Most teams overcomplicate memory. Start with conversation history in Postgres + a structured system prompt. Add vector search when your history exceeds context limits. Add agentic memory management only when your agent needs to learn across sessions.
Evaluation framework:
State management: this IS the state layer. You’re deciding what your agent remembers, how it retrieves it, and when it forgets. Highest complexity in the stack.
Lock-in risk: medium. pgvector is portable (it’s just Postgres). Specialized tools like Mem0 or Zep are harder to migrate away from.
Prototype-to-production gap: large. Demo memory works because context windows are big enough. Production memory breaks when conversations get long and your agent starts forgetting the important parts.
🎯 Takeaway: In-context memory breaks down when agents need to share memory across instances or maintain state across model provider switches. That’s where dedicated memory infrastructure (Letta, Zep, Mem0) earns its keep. Deep dive: Issue #5, What is RAG?
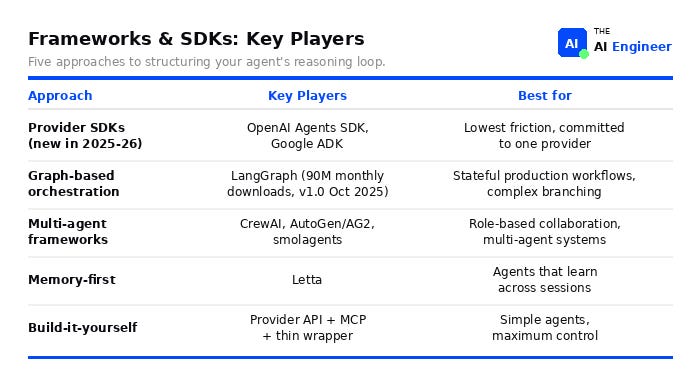
Layer 4: Frameworks & SDKs
In one sentence: How you wire together the model calls, tool use, and control flow that make your agent work: a provider's built-in toolkit (SDK), a graph-based framework like LangGraph, or raw code.
What changed since 2024:
Every major AI lab now ships its own agent SDK. OpenAI has the Agents SDK (evolved from Swarm). Google released ADK. Microsoft has Semantic Kernel and AutoGen. HuggingFace built smolagents.
Two years ago, LangChain was the only game. Now you pick between three camps: provider SDKs (fast to start, locked to one model), graph-based frameworks like LangGraph (portable, more setup), or no framework at all. That choice didn't exist in 2024.
LangGraph solidified as the graph-based orchestration leader: v1.0 released October 2025, production deployments at Uber, JP Morgan, LinkedIn, Klarna. LangChain agents are now built on LangGraph under the hood.7
The “build it yourself” camp grew: Teams that tried LangChain in 2024 and fought the abstraction are now writing thin wrappers over provider APIs + MCP. No framework means full control. This works until your agent needs state management or complex branching.
⚠️ Confusion Alert: “LangChain” and “LangGraph” are not the same thing. LangChain is the integration layer (model connectors, tool calling, prompt templates). LangGraph is the orchestration engine (state, control flow, graphs). Most production teams use both together, but LangGraph is where the agent logic lives.
🔥 The honest take: Most teams pick too much framework. If your agent calls a model and a few tools, you don’t need LangGraph. A provider SDK and a couple of tool calls will get you to production faster than any graph.
Evaluation Framework:
State management: Provider SDKs manage state for you. LangGraph makes you define every state transition explicitly. Build-it-yourself means you roll your own.
Lock-in risk: highest in the stack. Your orchestration code doesn't port. A LangGraph agent rewritten for CrewAI is a new codebase. Provider SDKs are worse: you're locked to one model too.
Prototype-to-production gap: large. Demo works because nothing goes wrong. Production means handling tool failures, retries, timeouts, and humans who need to approve before the agent acts.
🎯 Takeaway: The framework you pick determines your migration cost. Provider SDKs are fastest to start but lock you to one model. LangGraph is portable but complex. Building your own gives you full control until your agent outgrows your wrapper. MCP is the one layer that transfers across all three camps.
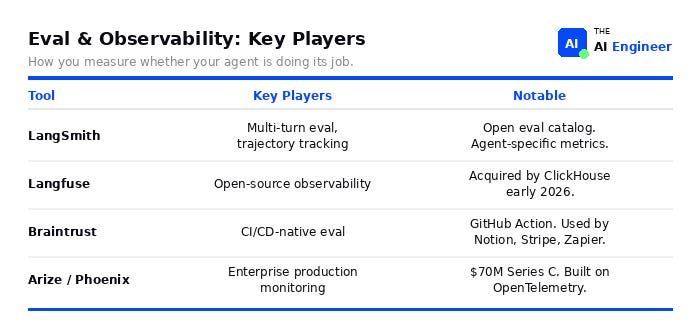
Layer 5: Eval & Observability
In one sentence: How you measure whether your agent is doing its job: tracing runs, scoring outputs, and catching regressions before users do.
What changed since 2024:
This layer barely existed. Now it’s the gap. LangChain’s State of Agent Engineering survey found 89% of teams with production agents have implemented observability, but only 52% have evals. That 37-point gap is where production quality dies.8
“Evaluation as infrastructure” is converging on three-tier. Fast checks on every PR (did the agent call the right tools?), nightly regression suites that use an LLM to judge output quality, and continuous production monitoring that alerts when agent performance drifts.9
New agent-specific benchmarks emerged: Context-Bench (memory management), Recovery-Bench (error recovery), Terminal-Bench (coding agents).
🔥The honest take: Most teams skip eval until something breaks in production. By then they’re debugging blind. The teams that don’t have this problem built evals before they deployed.
Evaluation Framework:
State management: your agent runs 12 steps. Step 3 picked the wrong tool. Steps 4-12 were doomed from there. If your eval only checks the final output, you’ll never know why.
Lock-in risk: moderate. Most tools export OpenTelemetry traces, so switching observability providers is doable. Switching eval frameworks means rebuilding your test suites.
Prototype-to-production gap: the biggest of any layer. Most prototypes have zero eval. You don’t feel the pain until production users find the failures for you.
🎯 Takeaway: Current eval tools are strongest for single-turn and tool-calling evaluation. Multi-agent evaluation, long-horizon task assessment, and evaluating agents that learn over time are all unsolved problems. If your agent does any of those, you’ll need custom eval infrastructure beyond what the platforms offer today.
Layer 6: Guardrails & Safety
In one sentence: How you stop your agent from doing things it shouldn’t: filtering inputs, authorizing tool calls, and validating outputs.

What changed since 2024:
Agent guardrails became a separate discipline from LLM guardrails. In 2024, guardrails meant input/output filters on a model. In 2026, your agent calls tools, spends money, and takes actions. Guardrails now means authorizing tool calls, enforcing rate limits, and validating what the agent actually did.
The “guardrails before action” pattern emerged. Teams that learned the hard way now enforce authorization at the tool execution layer, not the output layer. By the time you filter the response, the agent already sent the email.
OWASP published the MCP Top 10 (beta). First real security checklist for tool-connected agents.10
Deployment is still DIY. LangGraph Cloud and Bedrock Agents exist, but most production teams are still deploying with FastAPI and their own infra. This layer is where you'll spend the most unplanned engineering time.
🔥 The honest take: This is the least mature layer in the stack. No dominant framework, no established patterns. You’re writing policy code from scratch.
Evaluation framework:
State management: guardrails need to know what the agent is doing right now to decide what it shouldn't do next. That means tracking agent state in real time.
Lock-in risk: low. Most guardrails are custom policy code you write yourself. NeMo Guardrails is the closest thing to a framework, but you'll still write most rules from scratch.
Prototype-to-production gap: infinite. Your demo has no guardrails because nobody’s trying to break it. Production will.
🎯 Takeaway: Current guardrails tools focus on single-agent systems. If you’re running multi-agent workflows where agents delegate to each other, guardrail propagation across agent boundaries is an unsolved problem. You’ll need custom authorization logic.
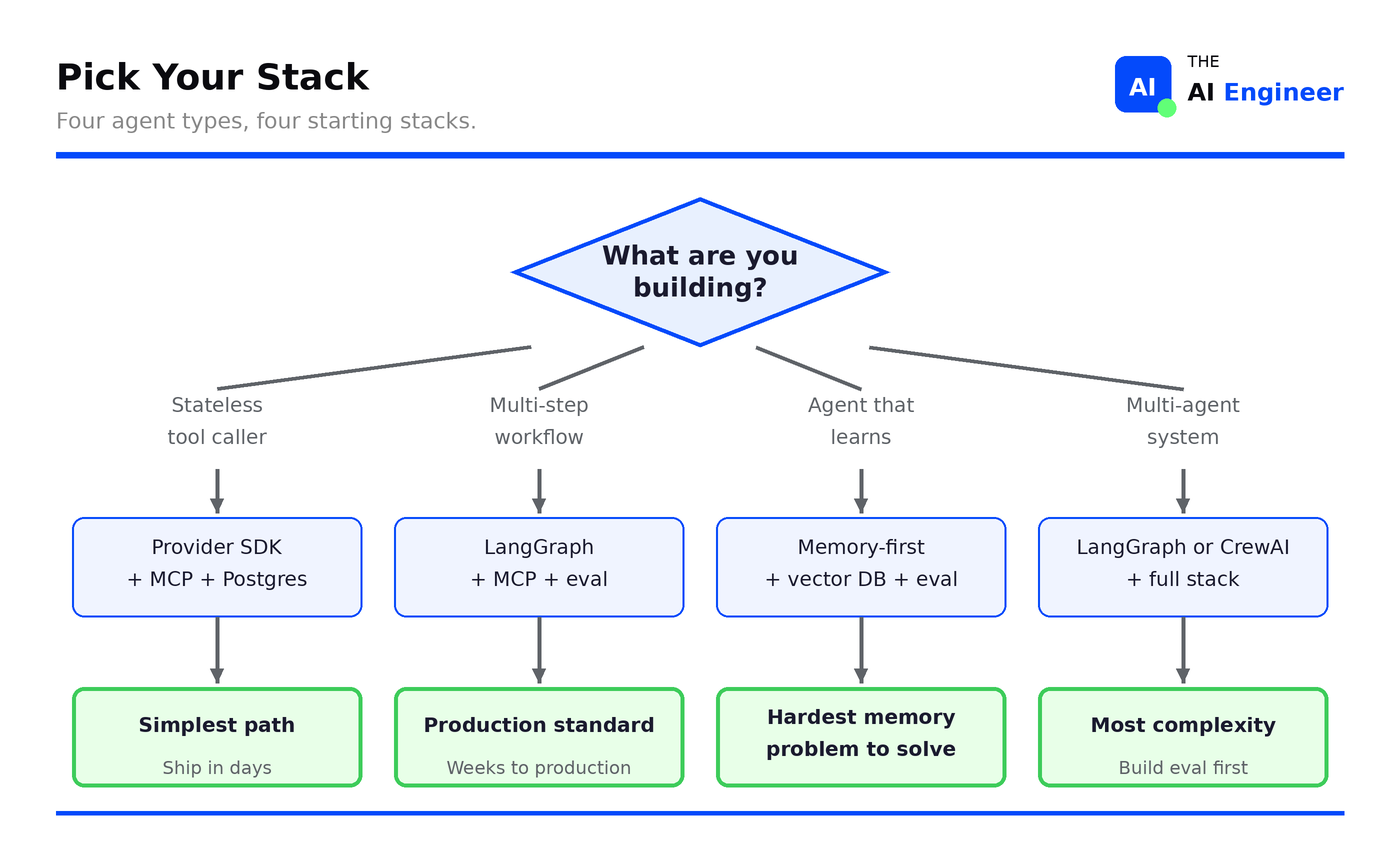
What Are You Building?
This is the decision that cuts through the framework confusion. The agent type determines which layers you invest in and which tools to pick at each one.
Stateless tool caller (answer questions from a knowledge base, look up an order, check inventory): Provider SDK + MCP + Postgres. No framework, no vector database. This is a weekend project.
Multi-step workflow (process a refund end-to-end, review a PR across 5 files, triage and route support tickets): LangGraph + MCP + eval. Steps depend on each other, things fail in the middle, humans need to approve before the agent acts. Build evals before you deploy because these agents break silently.
Agent that learns (remembers your preferences across sessions, gets better at your codebase over time, tracks project context across weeks): Memory-first architecture + vector DB + eval. Orchestration is the easy part. The hard part is deciding what to remember, what gets dropped and how you stop old context from polluting new answers.
Multi-agent system (agents that delegate to other agents, split a research task across specialists, run parallel workstreams): Full stack. Two agents passing context to each other is already hard to debug. Five is impossible without trace-level evals on every handoff. Build eval infrastructure before you build the second agent.
Coding Agents: All Six Layers in Action
Coding agents (Cursor, Claude Code, Codex, Windsurf) are the most proven application of the AI agents stack. All six layers, working together:
Layer 1 (Models): Inference serving hundreds of millions of daily requests. Cursor routes between Claude, GPT-4, and its own fine-tuned models depending on the task.
Layer 2 (Protocols & Tools): MCP servers connecting to editors, terminals, file systems, and git. This is how the agent reads your code and runs commands.
Layer 3 (Memory): Codebase-aware retrieval with reranking. The agent doesn’t read your whole repo. It retrieves the files that matter for this specific edit.
Layer 4 (Frameworks): Custom orchestration with RL loops. Not LangGraph, not a provider SDK. Purpose-built control flow for code generation, review, and iteration.
Layer 5 (Eval): Cursor retrains its acceptance-rate model every 90 minutes based on whether users accept or reject suggestions. That’s eval running in production, continuously.
Layer 6 (Guardrails): Sandboxed execution preventing runaway agents. The agent can write code and run it, but inside a container that limits what it can touch.
The AI Agent Stack Cheat Sheet
Every layer scored on the three questions from the evaluation framework:
How much state do you need to manage?
How much vendor lock-in can you tolerate?
How hard is it to go from demo to production?

The Bigger Picture
Most teams are building like it’s still 2024. They pick LangGraph before they know if they need state. They add a vector database before they’ve outgrown Postgres. They design multi-agent architectures before they’ve shipped one agent that works. The decision flowchart above exists because a tool-calling chatbot and a multi-agent research system share almost no infrastructure. Treat them the same and you’ll over-build the first and under-build the second.
The teams that got past this have three things in common:
They run evals on every deploy, not once a quarter.
Their guardrails sit at the tool call layer, not the output layer.
Their memory architecture was designed, not inherited from whatever the framework defaulted to.
Most teams ship the opposite: no evals, output-only filtering, and a system prompt that grows until the context window chokes. The gap isn’t talent or budget. It’s knowing which layers matter for your specific agent instead of half-building all six.
The stack is going to collapse. Provider SDKs are already absorbing memory, tool calling, and basic eval into a single API. By early 2027, most teams won’t build each layer separately. They’ll get an increasingly opinionated stack from their model provider and that will be fine for 80% of use cases. The other 20%, agents at scale where the defaults break, will still build custom at every layer. But even then, when something fails in production, you need to know which layer failed. That’s what this article is for.
What does your team’s agent stack actually look like? Which layers are solid, and which ones are you pretending don’t exist? Drop a comment below.
Tuesday: RAG, fine-tuning, or just better prompts? Most teams get the order wrong.
Where to Next?
🧱 Prerequisite: Issue #1, What is an AI Agent? (the think-act-observe loop this entire stack enables)
🔀 Related:
Issue #3, What is MCP? (the protocols layer in depth)
Issue #5, What is RAG? (one component of the memory layer)
📖 Go deeper: Inside Cursor’s Architecture (all six layers in a single product)
Letta, The AI Agents Stack (November 2024).
Anthropic, Donating MCP to the Agentic AI Foundation (December 2025).
StackOne, The AI Agent Tools Landscape (February 2026).
Invariant Labs MCPTox benchmark (September 2025).
Endor Labs, Dependency Management Report (January 2026).
Jason Liu’s Context Engineering series (August 2025),
LangChain/LangGraph 1.0 announcement (October 2025).
LangChain, State of Agent Engineering (December 2025).
Amazon, Evaluating AI Agents: Real-World Lessons from Building Agentic Systems at Amazon (February 2026).
OWASP, Top 10 for MCP Servers (December 2025).
“The agent stack is not the LLM stack. A chatbot needs inference and maybe RAG. An agent needs state management across multi-step execution, tool access governed by protocols, memory that persists across sessions, autonomous reasoning loops, and guardrails that constrain behavior in real time.”
i really like this post because you are doing a great job at explaining all of this while clearing up some really common misconceptions. this was a great read!
The 37-point eval gap is the most honest number in the whole piece. 89% built observability, 52% built formal evals. Teams that can see the logs but have no idea if it's working.
But that gap is downstream of a harder problem: most teams haven't defined success at the task level. You can't build evals without a spec. The tooling exists. The bottleneck is articulating what "done" looks like.
I've been running a self-improving agent for months (nightshift planning, dayshift execution, feedback loops). The stack converged fast -> provider SDK, Postgres, MCP. Done in weeks. What took months was boundary design: where human judgment ends, what failure modes actually matter, what counts as a good output. The infrastructure is a solved problem.
The hard part is still human.