

How Cursor Actually Works
The engineering behind the editor that codes for you.

The Pain
You install Cursor. You type a function signature. Before you finish the parameter list, the entire function body appears in gray text. You hit Tab, and it’s correct. Not autocomplete-correct. Edit-correct. You rename a variable on line 12, and the suggestions update the variable on lines 18, 24, and 31.
It feels like magic. It’s actually three engineering problems solved simultaneously:
Latency: the model has to respond before your next keystroke makes the suggestion stale.
Context: it needs to understand your codebase, not just the file you’re in.
Suggestion quality: showing a wrong suggestion is worse than showing nothing.
Every AI coding tool faces these three problems. Cursor’s answers to each one are more interesting than the product itself.
The answer isn’t “they plugged GPT-4 into VS Code.” Cursor built their own sparse model for completions, a speculative decoding trick that uses your existing source code to skip most of the generation work, and a reinforcement learning loop that retrains every 90 minutes based on what you accept and reject. The editor is the surface. The inference stack underneath is the product.
TL;DR
Cursor is a VS Code fork processing 400M+ AI requests per day, built by ~100 engineers, reaching $1B ARR in 24 months, faster than any B2B SaaS company in history .1
The core innovation is speculative edits: your existing source code serves as "draft tokens," pushing a 70B model to ~1,000 tokens/second (13x speedup) because most of an edited file is identical to the original.
A reinforcement learning loop retrains the Tab model every 90 minutes based on what you accept and reject, deploying new checkpoints multiple times daily at 400M+ requests.
The transparency gap is real. No SWE-bench scores. A removed blog post. Proprietary benchmarks. The engineering is impressive, but the evidence is harder to verify than it should be.
How Autocomplete Used to Work
Before Cursor, your editor already helped you write code. Language servers parsed your project in real time, offering completions based on static analysis: function names, variable types, method signatures. Type user. and the editor lists every method on that object. It’s fast, deterministic, and limited to what the compiler already knows.
GitHub Copilot changed the game in 2021 by replacing static analysis with a neural model. Instead of listing known methods, it predicted what you probably wanted to write next based on patterns across millions of repositories. The suggestions got dramatically more useful, but the architecture stayed simple: capture context from your current file, send it to a model, render the suggestion inline.
That architecture is the starting point for understanding what Cursor does differently, and why “just plug a better model into VS Code” was never going to be enough.
Why a Plugin Was Never Going to Work
Every AI coding tool faces the same bootstrapping problem: the model needs to see your code, process it, generate a suggestion, and display it before your next keystroke makes the suggestion stale. That’s a round trip from editor to server to model to editor, all within about 300 milliseconds.
GitHub Copilot solved this by running as an extension inside VS Code. The extension captures your cursor position, sends context to a model, and renders the suggestion inline. It works. But it works within VS Code’s extension API, which means Copilot can only do what VS Code’s API allows: insert text at the cursor, show inline suggestions, open a chat panel. If you want to do something VS Code doesn’t expose (like showing a multi-file diff overlay, or running a hidden second editor instance for validation, or intercepting the file system at the kernel level), you’re stuck.
Cursor’s founders made the fork decision in 2022. Aman Sanger, Sualeh Asif, Michael Truell, and Arvid Lunnemark, all from MIT, built Cursor as a direct fork of VS Code’s open-source codebase. This gave them full control over the editor’s rendering pipeline, file system hooks, and extension host. Every AI feature in Cursor, from speculative tab completions to the Shadow Workspace to Background Agents, required editor-level access that no plugin API provides.
⚠️ Confusion Alert: "Cursor is just a VS Code wrapper." It's not. A wrapper or plugin can only use what VS Code's extension API exposes. A fork means compiling and shipping your own editor binary, with full control over internals. The distinction matters: wrappers add features on top. Forks change what's underneath.
The tradeoff: every time Microsoft updates VS Code, Cursor has to merge upstream changes into a diverging codebase. That’s real engineering overhead. But it’s the price of building features that are architecturally impossible as plugins.
The Architecture
Cursor’s system has three layers that work together on every keystroke.
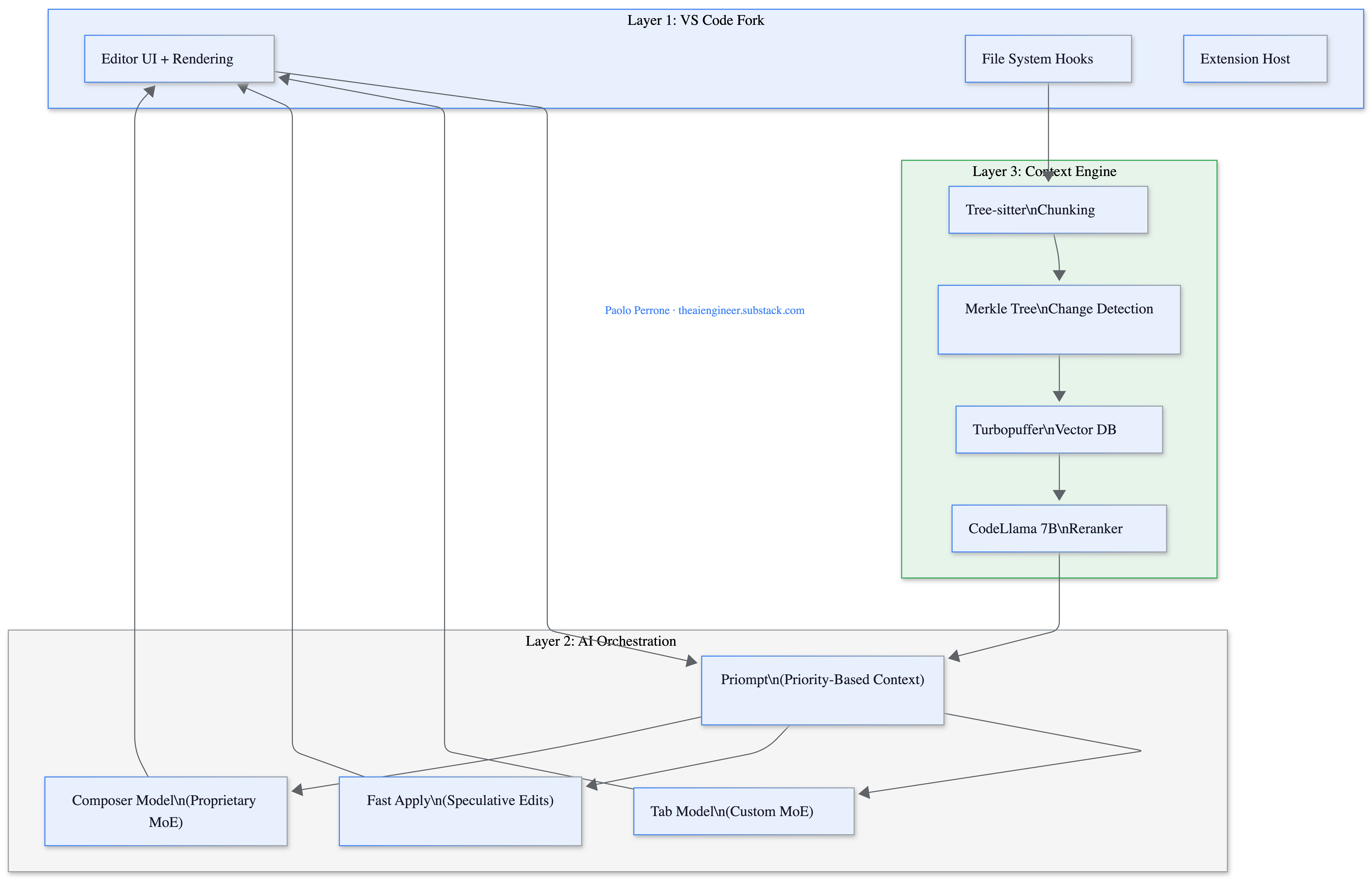
Layer 1: The Fork. The VS Code fork gives Cursor control over the editor’s rendering, file system, and extension host. This is what enables inline diff overlays, speculative suggestions that update in real time, and Background Agents running in isolated VMs.
Layer 2: AI Orchestration. This is where context meets models. Priompt (open-sourced at github.com/anysphere/priompt) compiles prompts as JSX components where each element has a priority score. When the total context exceeds the model’s token budget, lower-priority elements get dropped via binary search. It’s a simple idea that solves one of the hardest problems in production AI: deciding what to include when you can’t include everything.
Layer 3: Context Engine. Before any model sees your code, Cursor’s retrieval pipeline has already indexed your codebase. Tree-sitter splits code at function and class boundaries (not arbitrary line counts). A Merkle tree of file hashes syncs with Cursor’s server every ~5 minutes so only changed files get re-uploaded. Embeddings land in Turbopuffer, a serverless vector database backed by S3. When you query, a fine-tuned 7B CodeLlama reranker processes up to 500,000 tokens per query, made 20x cheaper through blob-storage KV caching2.
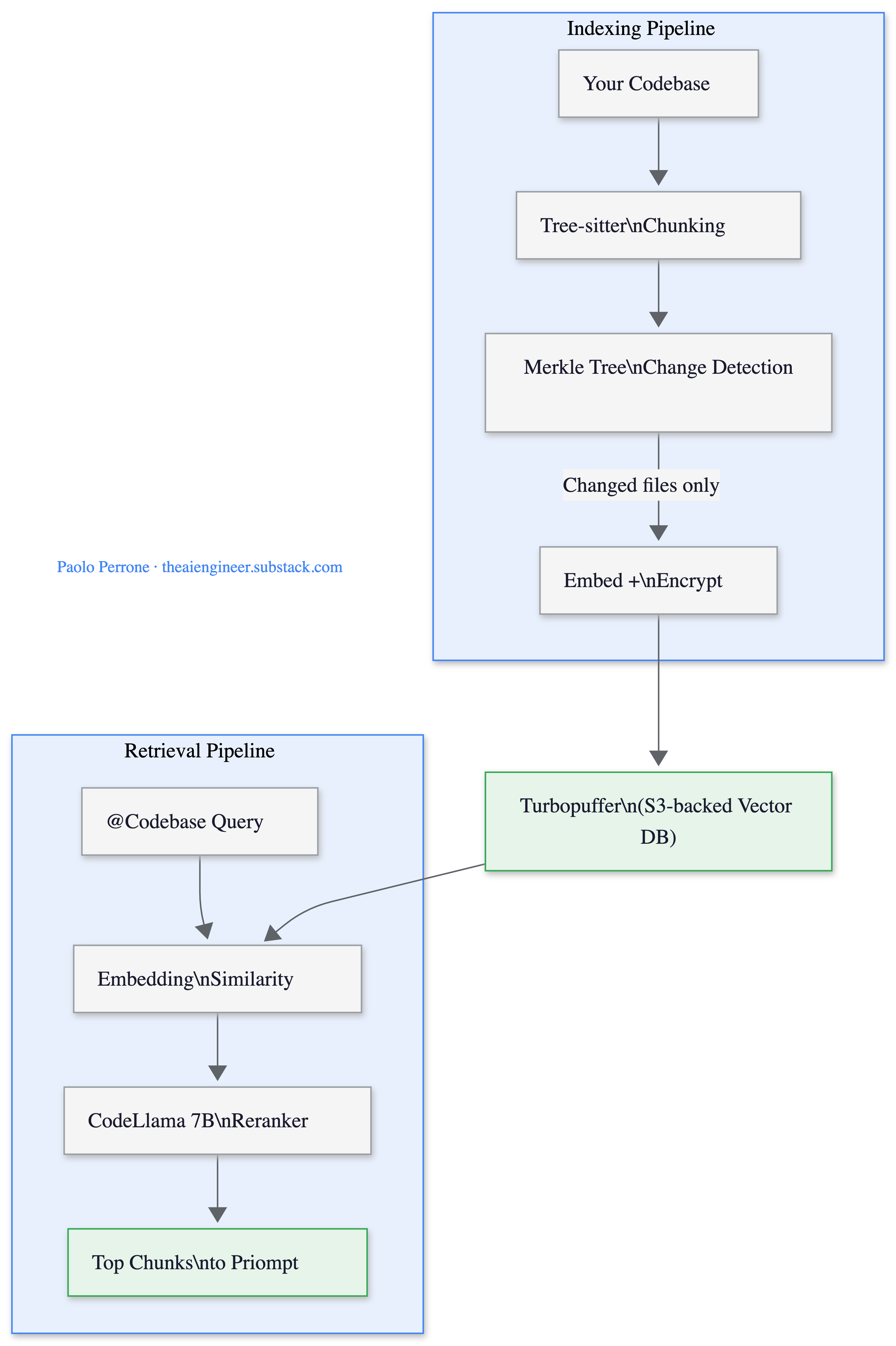
🔍 Deeper Look: Cursor open-sourced their prompt management library Priompt at github.com/anysphere/priompt. If you’re building any LLM application that needs to fit variable-length context into a fixed token budget, the priority-based dropping approach is worth studying. It’s more elegant than the “truncate from the end” approach most teams use.
The Diff Problem (and Why Speculative Edits Exist)
Here’s the core technical challenge that most AI coding tools quietly ignore: LLMs are terrible at generating diffs.
When you ask a model to edit a file, the obvious approach is to have it output a diff: “delete line 14, insert these three lines, change line 28.” This is how humans think about edits, and it’s token-efficient. The problem, as Aman Sanger explained on the Latent Space podcast, is that models get line numbers wrong constantly.⁴ Tokenizers handle numbers unpredictably, the model loses track of position in long files, and even small errors cascade. Sanger put a number on it: deterministic matching against diffs fails at least 40% of the time3. Only Claude Opus managed to output accurate diffs consistently.
So Cursor chose full-file rewrites. The model outputs the entire file with edits applied. More tokens, but deterministic. The problem moves from “did the model count lines correctly?” to “can we generate entire files fast enough?”
The answer is speculative edits: a novel variant of speculative decoding built specifically for code editing.
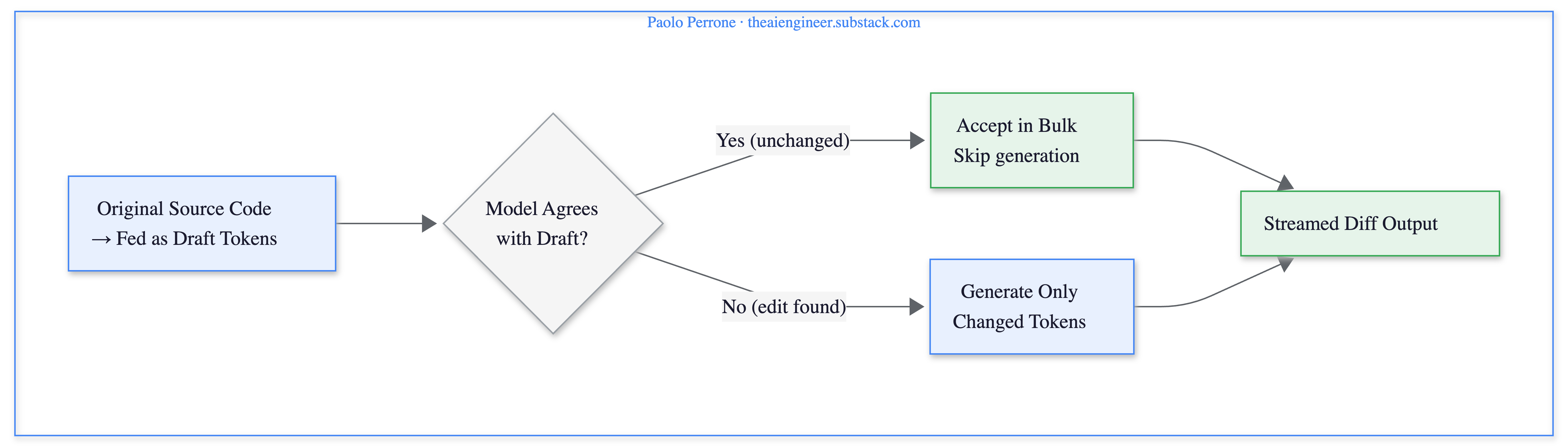
Standard speculative decoding uses a small, fast “draft model” to predict tokens, then a large “verifier model” checks them in parallel. But when you’re editing code, you don’t need a draft model. The file you’re editing is the draft. Most of the output will be identical to the original source.
The system chunks the original file and feeds those chunks as speculated output. The model processes them in parallel, accepting unchanged chunks in bulk. When the model predicts a change, it generates new tokens that diverge from the original. After the edit, it resumes speculating from the remaining unchanged code. Users see diffs streaming in real time during generation.
The Fast Apply model, a fine-tuned Llama-3-70b (internally nicknamed “llama-70b-ft-spec”), achieves roughly 1,000 tokens per second. That’s ~3,500 characters per second, a 13x speedup over vanilla Llama-3-70b and a 9x speedup over Cursor’s earlier GPT-4-based approach4. It runs on Fireworks AI, whose CEO noted that their FireOptimizer product originated specifically from optimizing Cursor’s workload.
🏗️ Engineering Lesson: Any task where AI modifies an existing file can use this trick. The original content serves as the draft tokens, so the model only generates what actually changed. Code editing is the obvious case, but the same approach works for contracts, configs, reports: anything where most of the output matches the input.
Tab RL: Reinforcement Learning at 400 Million Requests Per Day
Cursor’s Tab model started as a straightforward autocomplete system. The January 2025 Fusion update upgraded the infrastructure: context windows expanded from 5,500 to 13,000 tokens, the model learned to predict 25% more challenging edits, and changes could span 10x longer sequences. Server latency dropped from 475ms to 260ms5. At that point, Tab was generating over 1 billion edited characters per day.
The September 2025 Tab RL update was architecturally more radical. Instead of improving predictions alone, Cursor integrated the decision of whether to show a suggestion at all directly into the model’s policy using online reinforcement learning.
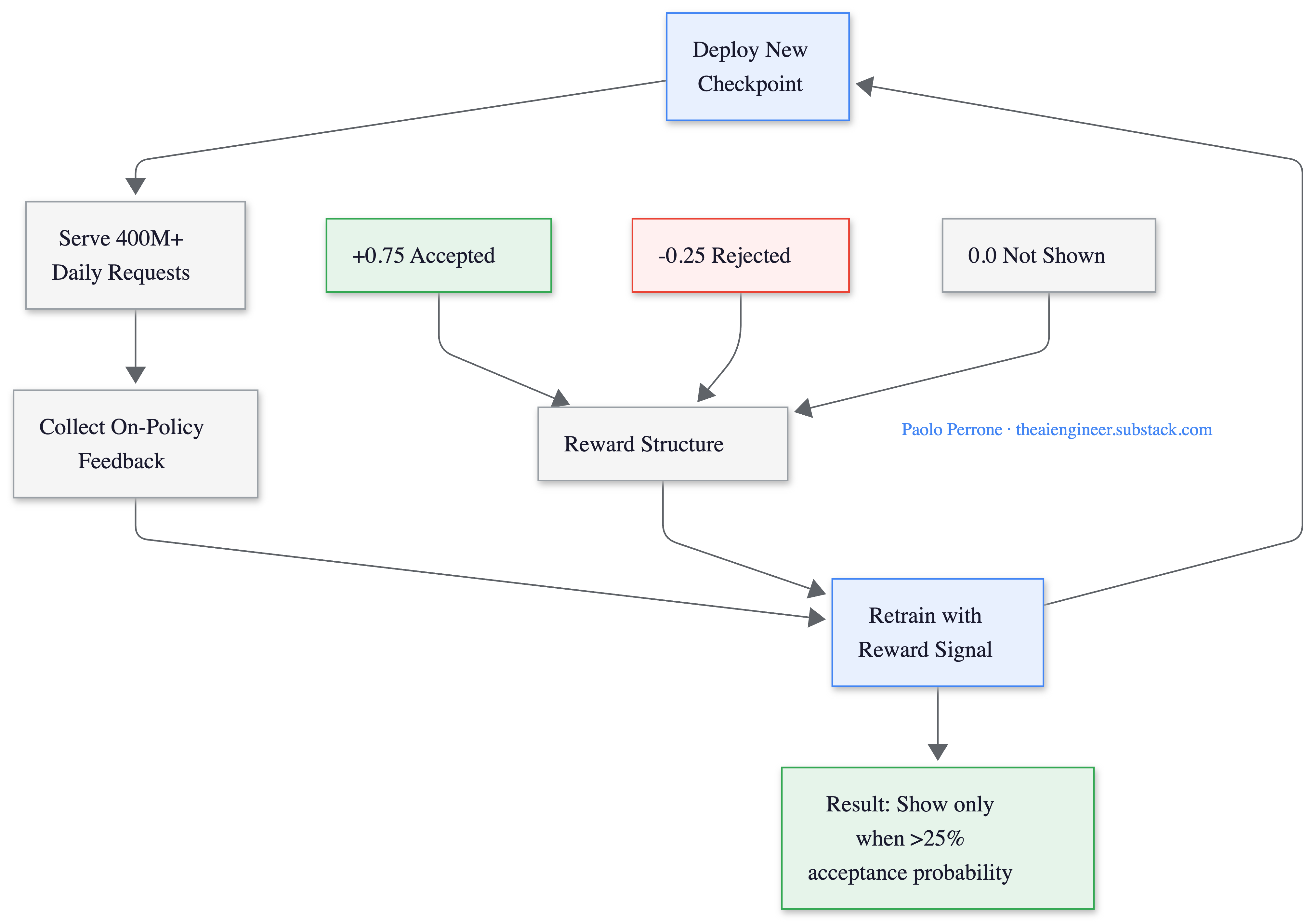
The reward structure is elegant: +0.75 for accepted suggestions, -0.25 for rejected ones, 0 for silence. The math means the model should only show a suggestion when estimated acceptance probability exceeds 25%. The result: 21% fewer suggestions with a 28% higher acceptance rate. Less noise, more signal.
What makes this unusual at scale: the full cycle of deploy, gather on-policy data, and retrain completes in 1.5 to 2 hours6. New checkpoints deploy multiple times per day. An OpenAI post-training engineer called this “the first large-scale demonstration of the advantage of real-time reinforcement learning.” This is not a batch training pipeline that ships monthly updates. It’s a model that learns from this morning’s coding sessions and improves by this afternoon.
What Broke (and What They Rebuilt)
Shadow Workspace (2024, removed January 2025). Cursor briefly ran a hidden second VS Code instance that linted and type-checked AI-generated code before the user saw it. Each instance consumed 500MB to 2GB+ of RAM. It was removed in version 0.45, superseded by the agentic architecture that validates code through tool use.
Bugbot’s evolution (July 2025 to January 2026). Bugbot, Cursor’s automated code review system, tells a cleaner evolution story. It launched with a pipeline architecture: eight parallel passes, each receiving the diff in a different order to nudge the model toward different reasoning paths. Majority voting filtered single-pass false positives. It worked, finding bugs in 52% of runs7.
Then in fall 2025, the team replaced the entire pipeline with a fully agentic architecture. Instead of fixed passes, the agent reasons over diffs, calls tools dynamically, and decides its own investigation depth. This required what the team called “aggressive prompting strategies,” the opposite of earlier versions that restrained models to minimize false positives. The result: resolution rate climbed from 52% to over 70%, bugs flagged per run nearly doubled (0.4 to 0.7), and the agent now reviews over 2 million PRs per month for customers including Rippling, Discord, and Airtable.
The infrastructure work was just as significant. The team rebuilt Git integration in Rust for speed and reliability, implemented rate-limit monitoring and request batching for GitHub’s API constraints, and added Bugbot Rules that let teams encode codebase-specific invariants (unsafe migrations, incorrect API patterns) without hardcoding checks.
🏗️ Engineering Lesson: Both the Shadow Workspace and early Bugbot followed the same arc: start with a pipeline (structured, predictable, constrained), then replace it with an agent (flexible, dynamic, harder to control). The Shadow Workspace was retired because the pipeline approach couldn’t justify its resource cost. Bugbot’s pipeline was replaced because the agentic approach was simply better. The lesson isn’t “agents always win.” It’s that rigid pipelines hit a ceiling, and knowing when you’ve hit it matters more than choosing the right architecture upfront.
My Honest Take
👍 What’s genuinely impressive:
Speculative edits are a real innovation. Using existing source code as draft tokens for speculative decoding is not a standard technique, and the 13x speedup it enables is what makes full-file rewrites practical at keystroke speed. The Tab RL system, deploying new model checkpoints multiple times daily from a 90-minute feedback loop at 400M requests, is operating at a scale and speed that very few teams have demonstrated in production.
The Bugbot evolution from pipeline to agent is a clean case study in knowing when to abandon a working architecture for a better one. The numbers are specific and sourced, which builds confidence.
✋ What’s concerning:
The transparency gap. Cursor has never published SWE-bench scores, relying exclusively on their proprietary Cursor Bench for model evaluation. Their most detailed technical blog post on speculative edits (cursor.com/blog/instant-apply) was removed in late 2024, with the details now preserved primarily through Fireworks’ blog and community reconstructions. The Composer model’s base architecture is undisclosed (it’s rumored to be built on GLM 4.6, a Chinese open-weights model, based on its fluent Chinese capabilities, but this is unconfirmed). For a product processing billions of daily completions across the majority of Fortune 5008, the gap between what Cursor claims and what outsiders can verify is wider than it should be.
Pricing transparency has been an issue. The June 2025 shift to credit-based pricing confused users, and heavy users report daily inference costs of $60-100/month. Cursor’s CEO issued a public apology and offered refunds.
🤔 The “could I build this?” check:
The core architectural ideas (speculative edits, priority-based prompt compilation, online RL for completion quality) are transferable. Priompt is open source. The speculative edits pattern works anywhere you’re modifying an existing document with AI.
But replicating the full system requires the inference fleet (tens of thousands of H100s), the training infrastructure, and the feedback loop from hundreds of millions of daily requests. The ideas are portable. The scale is not.
The One Thing to Remember
Cursor didn’t make AI better at coding. GPT-4, Claude, and Gemini were already good at writing code. What Cursor built is the infrastructure to make those models feel instant: speculative decoding that skips unchanged code, a reinforcement learning loop that learns what not to show you, and a context engine that retrieves the right 13,000 tokens from a million-line codebase.
The model isn’t the product. The latency engineering around it is.
What’s your Cursor setup? Auto model or manual model selection? Tab completions only, or full Composer mode? And if you’ve hit the performance wall on a large codebase, what did you do about it? Leave a comment below.
Where to Next?
📖 Go Deeper: “What is RAG?”: Cursor’s context engine is a production RAG system. Tree-sitter chunking, Turbopuffer embeddings, CodeLlama reranking. Here’s how the pattern works from first principles (next Tuesday).
🧱 Prerequisite: What is an AI Agent?: Bugbot’s evolution from pipeline to agent mirrors the industry’s shift. Here’s the think-act-observe loop driving it.
🔀 Related: Cursor vs Claude Code: now that you know how Cursor works under the hood, here’s how it compares to its biggest competitor.
Sacra estimates Cursor went from $1M to $100M ARR in 12 months (end of 2024), then to $500M by May 2025, crossing $1B by November 2025. Cursor's Series D press release (November 2025) confirmed the milestone alongside a $29.3B valuation.
Turbopuffer's Cursor case study: details the partnership: serverless vector database backed by S3/GCS/Azure Blob, with cold query latency ~500ms and warm queries at 8-10ms. Co-founder Aman Sanger confirmed the December 2023 switch from Pinecone: "After switching our vector db to @turbopuffer, we're saving an order of magnitude in costs."
Aman Sanger on the Latent Space podcast discussed the diff problem in detail: deterministic diff matching fails at least 40% of the time, and only Claude Opus managed accurate diffs consistently. This drove Cursor's decision toward full-file rewrites with speculative decoding.
Fireworks AI's blog on speculative decoding documents the Fast Apply integration, including the ~1,000 tokens/sec throughput and 2x latency reduction. CEO Lin Qiao noted that FireOptimizer originated from optimizing Cursor's workload. The original Cursor blog post at cursor.com/blog/instant-apply was removed in late 2024.
Cursor’s Fusion blog post (January 2025) documented the Tab model improvements: 25% more challenging edits per line, 10x longer changes, context expansion from 5,500 to 13,000 tokens, and server latency reduction from 475ms to 260ms. At the time, the system was generating over 1 billion edited characters per day.
Cursor's Tab RL blog post (September 2025) details the online reinforcement learning integration, the +0.75/-0.25/0 reward structure, the 400M+ daily request volume, and the 1.5-2 hour retrain cycle. An OpenAI post-training engineer called it "the first large-scale demonstration of the advantage of real-time reinforcement learning."
Cursor’s “Building a Better Bugbot” blog post (January 2026) documents the evolution from 8-pass pipeline to fully agentic architecture, with resolution rate improvement from 52% to 70%+ across 40 major experiments and 11 shipped versions.
Cursor’s Series D press release (November 2025) states “Serving the majority of the Fortune 500 and over 50,000 teams globally.”
The speculative decoding trick using existing source code is genuinely clever. Most AI coding tools treat your codebase as context - Cursor treats it as a prediction shortcut.
This kind of architectural differentiation is why the 'best model wins' narrative is wrong. Tool engineering matters more than model capability for daily coding work.
I ended up building my workflow around multiple tools for this reason - Cursor for inline edits, Claude Code for autonomous execution, GPT for quick lookups. Different architectures solve different problems.
Explored the multi-tool approach: https://thoughts.jock.pl/p/multi-model-ai-workflow-2026-gpt-claude-gemini
The 90-minute RL retraining loop is the detail that stood out most. That's not just personalization - that's the tool learning your codebase in real time.