

What is Agent Prompt Engineering?
The same prompt that runs a chatbot quietly breaks an agent.

🧭 Part 14 of the 🤖 Agents course
Agent prompt engineering is the practice of designing the instructions, tools, and context for a model that runs in a loop and takes actions. It covers the system prompt, the tool descriptions, the memory the agent carries between steps, the reason-act loop, and the stop conditions that keep it on task.
TL;DR
Prompting an agent is onboarding. It is closer to writing a new hire’s job description and standard operating procedure than to asking one clever question. The model is the new hire; the prompt is everything you set up around it.
A chatbot prompt breaks the moment the model can act. An agent runs in a loop with tools and memory, so a prompt that never set its role, its tools, its context, or a stop condition lets it improvise and drift.
There are five levers. The system prompt, the tool descriptions, the context and memory, the reason-act loop, and the stop conditions and guardrails. Agent prompt engineering is tuning these five.
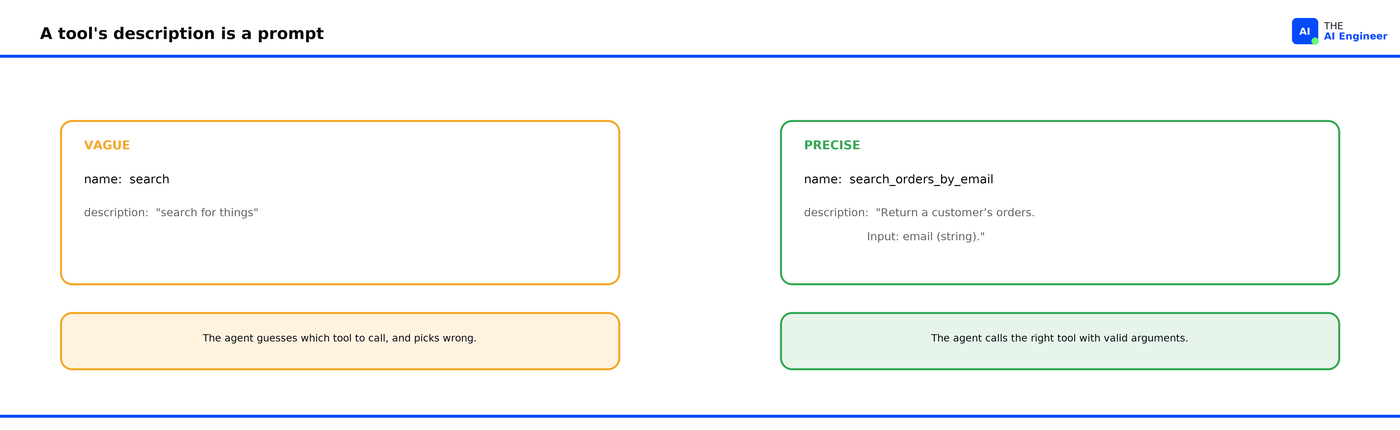
Tool descriptions are the highest-leverage prompt you write. A tool’s name and description are instructions the model reads on every step, and vague ones are where agents go wrong.
It is measurable. OpenAI found that three system-prompt reminders (persistence, tool use, and planning) lifted a coding agent’s score on SWE-bench Verified, a benchmark of real GitHub issues, by close to 20%.
Before Agents: The Chatbot Prompt
You write an instruction, maybe a couple of examples and a format to follow, and the model writes one answer back. That is the chatbot prompt you already know, and it is mostly about wording: say what you want clearly, show an example or two, pin down the output shape.
That prompt does exactly one turn: no memory of the previous turn, no tools, no decisions of its own. For a question that has an answer, that is plenty. It breaks the moment you wrap a loop around that same model and let it act. We cover that step in What is an AI Agent?.
Why the Chatbot Prompt Breaks
Turn that same model into an agent and one thing changes: it runs in a loop. It reads the situation, picks a step, calls a tool, sees the result, and decides again, around and around until it judges the job done. Four new failure modes open up the moment that loop starts.
Wrong actions. The agent does not just answer, it takes actions, so a single wrong decision can delete a file, send an email, or force-push to main.
Runaway loops. The agent decides its own next step, so with no rule that says “stop,” a confused one keeps calling tools, turning a quick task into an endless, costly loop.
Context overflow. A long task fills the window with tool output and old steps, burying the original goal.
Prompt injection. The model cannot tell your instructions apart from the text its tools return, so a hostile line hidden in a web page or file can hijack what it does next.
⚠️ Confusion Alert: It is tempting to fix a misbehaving agent with a longer, more detailed prompt, more examples, more step-by-step scripts. That usually backfires. Piling in examples makes an agent imitate them rigidly, and over-scripting the loop fights the model’s own planning. Give the model only what the current step needs, and cut the rest.
How Agent Prompt Engineering Works
Agent prompt engineering comes down to five levers, each sitting on a different part of the loop.
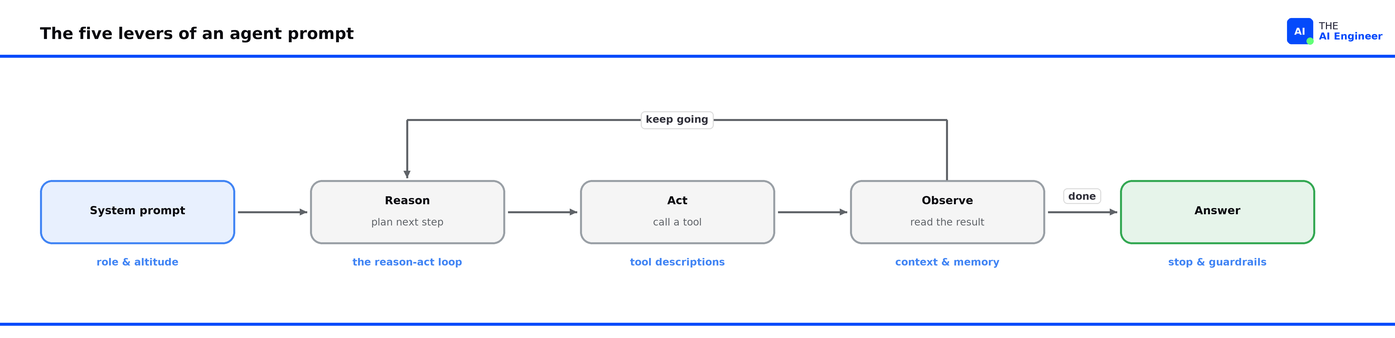
The system prompt sets the role and the altitude. It tells the agent who it is, what it owns, and how much latitude it has. The hard part is altitude. Too vague and the agent invents its own goals; too prescriptive and you are back to scripting every step. Write at the right altitude: specific enough to steer, open enough to let the model plan1.
Tool descriptions are prompts, and the highest-leverage ones you write. Each tool you give the agent has a name, a description, and an input schema. On every step the model reads them to decide which tool to call and with what arguments, the mechanism we cover in What is Function Calling?. The description is the instruction the model follows, so a vague one produces vague behavior. A tool called search described as “search for things” leaves the model guessing; the same tool named search_orders_by_email, described as “return a customer’s orders for a given email,” tells it exactly when and how to call it. Anthropic found that small refinements to these descriptions move an agent’s reliability more than almost any other change2.
Context and memory decide what the model can see. The context window is finite, so a long-running agent has to manage it: pull in information only when a step needs it, compact old turns, and push durable state into external memory. That last move is What is Agent Memory?. It matters because of context rot: as the window fills, the model’s recall of any one part drops, even when the context is clean. The Manus team’s fix is to use the file system as the agent’s long-term memory and to rewrite the agent’s to-do list each step, so the goal stays in the model’s recent attention as the task drags on3.
The reason-act loop is where prompting turns into behavior. What makes an agent more than a single call is interleaving reasoning with action: think a step, take an action, read the result, think again4. That pattern comes from the ReAct work, which showed that letting a model reason between tool calls makes it plan and self-correct instead of guessing in one shot5. Underneath, an agent is a model plus three things you supply: a plan, a memory, and tools, the anatomy laid out in What is an AI Agent?. The prompt connects them.
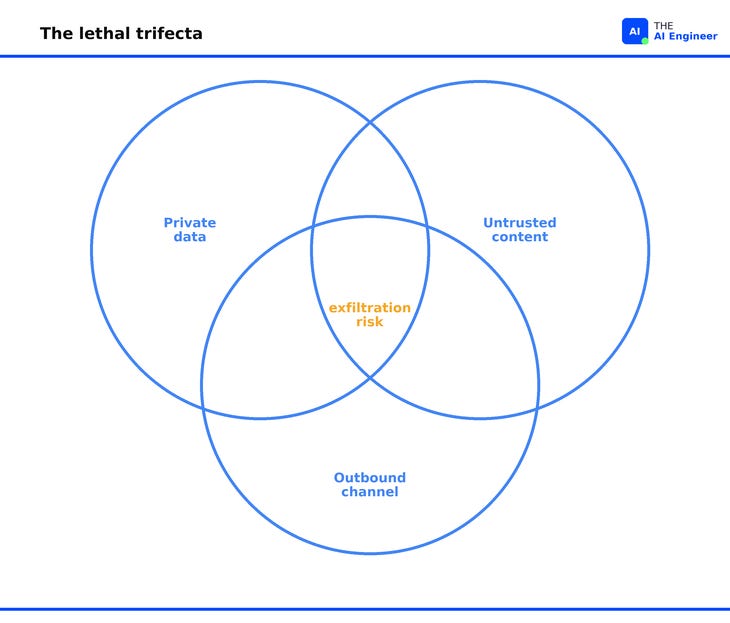
Stop conditions and guardrails decide when it ends and what it may touch. An agent needs to know three things: when the job is done, when to escalate to a human, and which actions are forbidden. That last one is where most agent disasters live. It is the subject of What are AI Agent Guardrails?. It is a security boundary too. Simon Willison’s “lethal trifecta” names the danger: an agent with access to private data, exposure to untrusted text, and a way to send data outward can be talked into leaking, because it cannot reliably separate your instructions from instructions hidden in the content it reads. Which tools an agent holds is a safety decision, and you make it in the prompt6.
The cheapest security win here is three lines of system prompt. OpenAI’s prompting guide for GPT-4.1 recommends three short reminders in an agent’s system prompt: (1) keep going until the task is fully resolved, (2) use your tools instead of guessing, and (3) plan before each call and reflect after. Adding those three reminders raised the model’s score on SWE-bench Verified, a benchmark of real GitHub issues, by close to 20% on OpenAI’s own internal eval7.
🔍 Deeper Look: The clearest short read on when you even need an agent loop is Building Effective Agents (Anthropic, December 2024). Its key advice: start with the simplest thing that works, and add agentic steps only when simpler solutions fall short and the added complexity demonstrably improves outcomes.
Who Is Actually Doing This
Cognition, the team behind the Devin coding agent, calls context engineering the single most important job of an agent builder. Their two rules: share the full context and the full trace of what the agent did, never fragments, because sub-agents working from partial context produce conflicting results. The teams shipping real agents obsess over context like this; clever wording is the easy part8.
The Manus team, building a general assistant agent, found the same lesson from the performance side. They design around the model’s key-value cache. When a tool should be unavailable they mask it instead of deleting it mid-run, because deleting a tool the agent has already seen breaks the cache and confuses the model. Their most counterintuitive finding: adding few-shot examples to an agent prompt can hurt, because the agent starts mechanically repeating the pattern in the examples9.
This is also why agents that look great in a demo fail in production: the demo never ran long enough to fill the context window or meet a malicious input.
The Honest Take
“Agent” is the most overhyped word in AI right now. The shift it names is real: a model that plans and calls tools in a loop does work a chatbot cannot. The autonomy it implies is mostly oversold; the agents worth running in production are narrow, supervised tool-loops, and their reliability comes from unglamorous context discipline rather than any single clever prompt.
That is also why prompting cannot make an agent safe. A stop condition caps how far a runaway loop runs, but it cannot prove the agent stopped for the right reason. Prompt injection is worse: it has no prompt-level fix at all, because once an agent can read untrusted text, reach private data, and act in the world, no wording stops it from obeying a hostile instruction. The only dependable defense is architectural, removing one of those three powers.
Prompting also has a ceiling. Past a point, more detail constrains more than it guides, especially with reasoning models, which do better with a clear goal and a few hard limits than with a step-by-step script that boxes in their own planning.
How much you invest in each lever scales with the stakes. A read-only research agent needs light guardrails. An agent that can move money or delete records needs the opposite, and the prompt is where you set that ceiling before it ever runs.
The One Thing to Remember
The move from chatbot to agent is the move from writing a question to onboarding an employee. The model is the new hire, capable and a little too eager, and the prompt is the role, the tools, the notes, and the limits you hand it on the first day. Get those right and the agent stays on task. Leave them implicit and it improvises, which is the one thing a system holding real tools should never do.
💬 What is the first guardrail you add to a new agent: the stop condition, the tool whitelist, or something else? Tell me in the comments.
🔜 Friday: What Does NVIDIA’s Vera CPU Actually Do?, the chip NVIDIA built so its GPUs never sit idle.
FAQ
What is agent prompt engineering?
It is the practice of designing everything an LLM agent reads and is bounded by: the system prompt, the tool descriptions, the context and memory it carries between steps, and the stop conditions and guardrails. The goal is an agent that runs a tool loop and stays on task.
How is it different from regular prompt engineering?
Regular prompt engineering tunes the wording of a single request. Agent prompt engineering configures a model that loops, calls tools, and keeps state, so it has to cover tool design, context management, and when to stop, none of which a one-shot chatbot prompt needs.
Which lever matters most?
For most teams, tool descriptions and context management. A tool’s name and description steer what the agent does on every step, and a context window that fills with noise is the most common reason a capable agent drifts off task.
How do you stop an agent from looping forever?
With explicit stop conditions in the prompt and the code that runs it: a definition of done, a cap on the number of steps, and a rule for handing off to a human. The agent also needs to know which actions are off-limits, so a confused loop cannot do real damage.
Do better models remove the need for it?
No. Stronger models follow instructions and plan better, which makes good prompting more useful. They still need to know their role, their tools, their limits, and when to stop.
🗺️ If you are transitioning into AI engineering, How to Break Into AI Engineering in 2026 is the full roadmap on getting there.

Effective context engineering for AI agents, Anthropic, September 2025
Writing effective tools for AI agents, Anthropic, September 2025
Context Engineering for AI Agents: Lessons from Building Manus, Manus, July 2025
LLM Powered Autonomous Agents, Lilian Weng, June 2023
ReAct: Synergizing Reasoning and Acting in Language Models, Yao et al., arXiv 2210.03629, October 2022
The lethal trifecta for AI agents, Simon Willison, June 2025
GPT-4.1 Prompting Guide, OpenAI, April 2025
Don’t Build Multi-Agents, Cognition (Walden Yan), June 2025
Context Engineering for AI Agents: Lessons from Building Manus, Manus, July 2025