

What Does Pinecone Actually Do?
What you’re paying for, and what you’re not.

🧭 Part of the 🔍 RAG & Search course
You’re three weeks into building a RAG system. You’ve chunked your documents. You’ve generated embeddings with text-embedding-3-small and watched the OpenAI bill climb. You’ve got 8 million vectors sitting in a Python dict and queries are now taking 4 seconds because you’re doing brute-force cosine similarity in a loop. Somebody on the team says “just use Pinecone.”
You go to pinecone.io and read about Assistant, Inference, BYOC, slabs, namespaces, dedicated read nodes, and something called serverless that is somehow different from the serverless you already use. The site tells you Pinecone is a vector database. You knew that. The questions you actually have are which kind of vector database it is, what the architecture is doing that pgvector isn’t, whether the bill is justified, and whether the company will still exist next year.
TL;DR
Pinecone is a fully-managed, multi-tenant vector database. You send vectors, you query vectors, you don’t run servers.
The 2024 rebuild changed the product. The serverless architecture separates storage from compute, made the old pod-based pricing obsolete, and is the only configuration new accounts can provision.
The architecture is the IP. Geometric partitioning over blob storage, a freshness layer that catches recent writes, and namespaces that scale to hundreds of thousands of tenants per index. None of this is in pgvector.
The category is commoditizing fast. pgvector, Qdrant, Weaviate, Milvus, and LanceDB all do “good enough” vector search now, and Pinecone reported $14M in revenue for 2025, down from $26.6M in 20241 .
Use Pinecone if you’re shipping a RAG product to multiple tenants, you don’t want to operate a database, and your traffic is bursty. Don’t use it if you already run Postgres at scale and your vector workload fits in pgvector’s ceiling.
Before Pinecone, get solid on vector databases
A vector database stores high-dimensional numeric arrays (embeddings) and answers one question fast: given this query vector, what are the K nearest vectors in my collection? “Nearest” means by cosine similarity, dot product, or Euclidean distance. K is usually 5 to 50.
If you’re fuzzy on what’s in those arrays, read What are Embeddings? first. The short version: an embedding model takes text, an image, or audio and outputs a fixed-length array of floats (768, 1024, 1536, 3072 dimensions are common). Two pieces of content with similar meaning produce vectors that are close to each other in that space. Vector search is how you turn “find me semantically similar things” into a database query.
The hard part isn’t storing the vectors. It’s searching them at scale. Brute-force comparison against 100 million vectors takes too long. Every vector database is, at its core, a wrapper around an approximate nearest neighbor (ANN) algorithm: HNSW, IVF, IVF-PQ, or some proprietary variant. Each of these trades a small amount of recall for a massive speedup. The differences between vector databases come down to (1) which ANN algorithm they use, (2) how they shard and scale, (3) how fast they accept writes, (4) how they handle metadata filtering, and (5) whether you have to operate them yourself.
Pinecone’s bet, since day one, has been that engineers will pay a premium to never see those four parameters in a config file.
The company in three acts
Pinecone was founded in 2019 by Edo Liberty. Liberty previously ran Amazon’s research division on AWS AI. Before that he was a research scientist at Yahoo Labs, working on streaming algorithms and randomized matrix decompositions. Streaming algorithms compute over data that doesn’t fit in memory. That’s also the core problem of vector search at scale. The founder picked a problem he had spent a decade preparing for.
Act 1: Pods (2019 to 2023). Pinecone’s original architecture was the standard search-engine playbook: shard the index across pods, replicate for availability, scatter-gather queries across all shards, gather results, return top-K. You picked a pod type (p1, s1, or p2), a pod size (x1 through x8), and a replica count. You paid for that capacity 24/7, whether you queried it or not. By April 2023 the model had carried the company to $138M raised, a $750M valuation2 , and customer logos including Shopify, HubSpot, Zapier, and Gong.
Act 2: Serverless rebuild (Jan 2024). The pod model worked fine for steady, high-QPS workloads, but most real RAG traffic isn't steady. Customers were paying for capacity they used 5% of the time. The serverless rewrite separated reads, writes, and storage into independently-scaling layers and pushed the source of truth into blob storage. Pricing flipped from "provisioned pods per month" to "read units, write units, storage GB." For variable workloads the cost difference was 10x to 50x in customers' favor3.
Act 3: Adjacencies (2025 to now). With the serverless core stabilized, Pinecone moved up the stack into three adjacent products of decreasing strategic weight.
Pinecone Inference is the load-bearing one: it runs hosted embedding and reranking models so RAG teams don’t need a separate OpenAI or Cohere call before storing text, which keeps the workload (and the bill) inside Pinecone.
Pinecone Assistant is a hosted RAG chat product that handles ingestion, retrieval, and generation behind one API, aimed at teams who would otherwise build the same plumbing themselves.
BYOC (Bring Your Own Cloud) runs Pinecone inside the customer's own AWS account. Banks, healthcare companies, and government buyers can't ship data to a third-party cloud, and BYOC is how Pinecone sells to them4.
What you’re actually buying: the serverless architecture
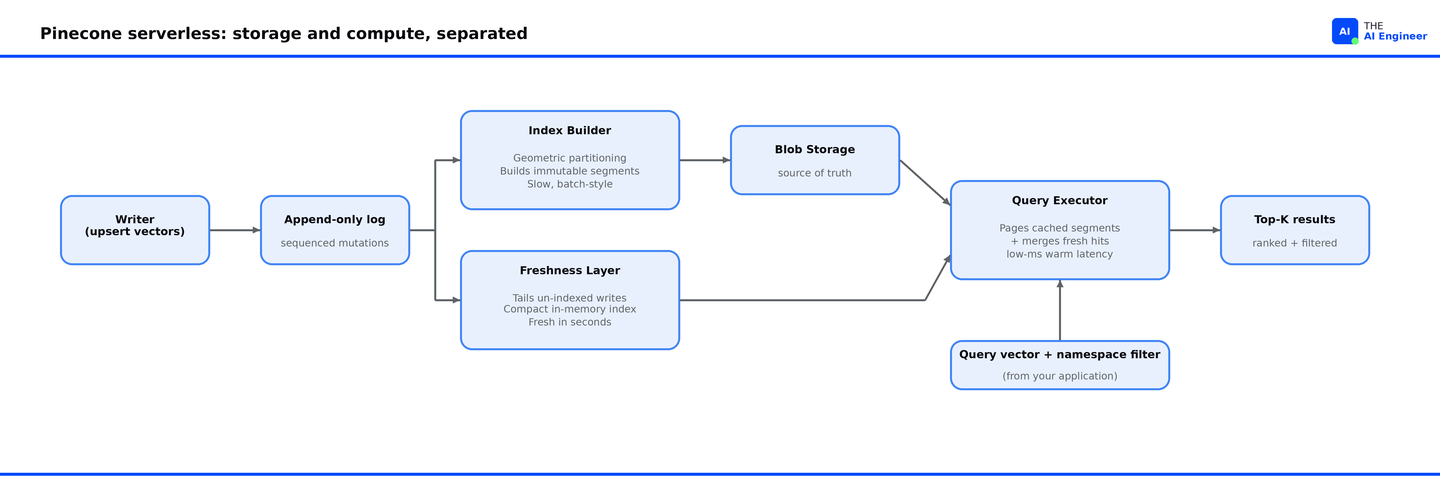
Pinecone’s serverless design makes four architectural decisions that traditional vector databases punt on: holding the index in blob storage instead of RAM, catching recent writes in a parallel freshness layer, partitioning by namespace so tenant traffic doesn’t share resources, and applying metadata filters during the ANN search rather than after.
The index lives in blob storage, not RAM. Stock vector databases use HNSW, an algorithm that builds a navigable graph of all the vectors and holds the whole graph in memory. Pinecone's index lives in distributed object storage (think S3-class), which is far too large to fit in RAM. Loading the entire index on every query would cost seconds of latency and gigabytes of memory. So Pinecone needs to load only the parts of the index a given query actually needs. Geometric partitioning is that mechanism: the index builder divides the vector space into regions, picks a representative point for each region (a "centroid"), and assigns each new vector to the closest centroid's region. Each region becomes its own file, stored once and never modified. At query time, the executor only loads the files that overlap with the query vector's neighborhood. For an index of one billion vectors, cold-start latencies are a few seconds for typical datasets and can hit 20 seconds5 . Warm queries run in single-digit to low-double-digit milliseconds.
A freshness layer catches new writes in seconds. Geometric partitioning is a one-shot build. If a new vector arrives, the index builder has to find the right region, rewrite the entire region file with the new vector inside, and replace the old file. That's expensive. RAG corpora change constantly: people add documents, redact paragraphs, edit pages. If every edit waited for the index builder to rewrite the affected region file, new documents would take minutes to become searchable. Pinecone solves this with a parallel process. Every write first lands in a sequenced write log (an append-only file that records mutations in order). The index builder reads from that log in batch. The freshness layer reads from the same log but only the writes the index builder hasn't processed yet, and holds them in a small in-memory index that's cheap to rebuild. At query time, the executor searches both the slow on-disk index and the fast in-memory fresh index, then merges the results. This pattern (slow batch index plus fast streaming index, merged at query time) is called a lambda architecture.
Namespaces replace “one index per customer” with one index, many partitions. Notion AI has millions of users, each with their own private notes that have to be searched separately. There are two naive ways to do this. The first is to put everyone’s vectors into a single shared index and tag each vector with a user ID. The second is to spin up a separate index per user. Both approaches break at scale. The shared-index approach forces every query to filter by user ID, which means the database scans everyone’s data to answer one person’s question. The index-per-user approach works until you hit a few thousand users. Past that, every deployment, credential rotation, and monitoring change has to be applied to thousands of separate indexes, and the team spends more hours managing the index fleet than doing anything else.
Namespaces are the third option. When you write a vector to Pinecone, you tag it with a namespace string (”customer-acme”, “customer-globex”), and Pinecone stores the vectors for each namespace in their own set of region files. When a query arrives with a namespace tag, the executor only loads region files belonging to that namespace. A query against customer-acme never reads a byte of customer-globex‘s data, which removes the shared-index scan problem. All namespaces share one API endpoint, one set of credentials, one monitoring surface, so adding a million customers means writing a million new namespace strings, not provisioning a million indexes. That removes the operational problem.
The cost win: Pinecone’s executor only loads region files when a query needs them, so region files for idle namespaces sit in blob storage and cost nothing. In a SaaS product where most customers are idle at any given moment, that produces a 50x cost reduction over running one index per customer.
Pre-filtering applies metadata filters during the ANN search. A query like “find documents in team=eng similar to this question” combines a vector similarity match with a metadata filter. Most vector databases run them in sequence: the ANN search returns the top 100 most similar vectors, then the metadata filter throws out the ones where team isn’t eng. If your filter is selective (say, 1% of vectors qualify), the top 100 from the unfiltered search will mostly get discarded, and you have to re-run with a larger K to get any results back. On a 100M-vector index, that means scanning 100M vectors to surface 10 useful ones. Pinecone’s serverless tier consults the filter at each step of the ANN traversal, so the search never enters regions where no vector could pass the filter. On the same query, it scans roughly 1M vectors instead of 100M. Every multi-tenant RAG product runs a “this customer’s data only” filter on every query, which is why pre-filtering is what makes the economics work.
What it actually looks like to use
Three lines of Python and you have an index:
from pinecone import Pinecone, ServerlessSpec
pc = Pinecone(api_key="...")
pc.create_index(
name="docs",
dimension=1536,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1"),
)
index = pc.Index("docs")Inserting and querying is just as flat:
index.upsert(
vectors=[
{"id": "doc-1", "values": [...], "metadata": {"team": "eng", "year": 2026}},
{"id": "doc-2", "values": [...], "metadata": {"team": "sales", "year": 2026}},
],
namespace="customer-acme",
)
results = index.query(
vector=[...],
top_k=10,
namespace="customer-acme",
filter={"team": {"$eq": "eng"}},
)If you need embedding generation in the same call, Pinecone Inference will do it:
embeddings = pc.inference.embed(
model="multilingual-e5-large",
inputs=["hello world", "another doc"],
parameters={"input_type": "passage"},
)With Inference, the embedding call and the upsert happen in the same network round trip, so the workload (and the latency budget, and the bill) stay inside Pinecone instead of bouncing through OpenAI or Cohere on the way in.
The competitive landscape
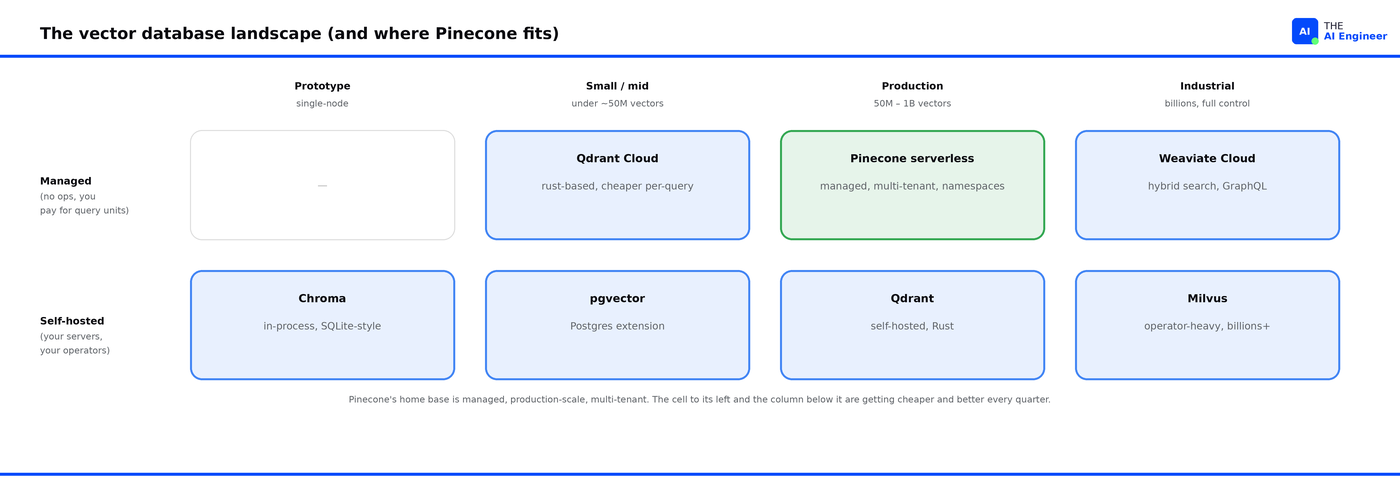
Three years ago, “I’m using Pinecone” was the default answer if you were building a RAG system. Today the answer is more complicated: pgvector ships with every cloud Postgres, Qdrant Cloud is roughly half the price for equivalent workloads, and “vector database” has become a checkbox feature inside Snowflake, Databricks, and MongoDB Atlas.
pgvector is the largest competitor by deployment count, because it ships as a PostgreSQL extension on every major managed Postgres (RDS, Cloud SQL, Supabase, Neon). Most engineering teams already run Postgres, so adding vectors to an existing database is operationally cheaper than introducing a new one, even if pgvector’s vector search is not as fast or as scalable as Pinecone’s. Timescale’s pgvectorscale extension pushed pgvector’s ceiling further, hitting 471 QPS at 99% recall on 50M vectors6 . For most teams under 50M vectors, pgvector is now good enough.
Qdrant is the open-source contender. Rust-based, fast, supports complex filtering, and has a managed cloud tier at roughly half the price per query of Pinecone’s serverless at comparable workloads.
Weaviate went deepest on hybrid search (dense + sparse + keyword) and has the best out-of-the-box GraphQL API. The managed pricing is competitive with Pinecone at small scale, less so at large scale.
Milvus is what you pick when you’ve outgrown the others and have an engineering team that wants control. It scales to billions of vectors, but typically requires a 2 to 3 person platform team to operate at production scale.
Chroma owns the prototyping segment. SQLite-style ergonomics, in-process for early dev work, and easy to swap out when you outgrow it.
For the head-to-head benchmark comparison and a decision tree across the top five, see: Pinecone vs Weaviate vs Qdrant vs Milvus vs Chroma.
The honest take
Pinecone is the cleanest managed vector database on the market. No other major vector database has shipped storage-compute decoupling, a freshness layer, namespace-scoped multi-tenancy, and pre-filtering as four integrated architectural decisions at production scale. If your job is to ship a RAG product and your team’s time is more expensive than your infrastructure bill, paying Pinecone’s premium is rational.
Pinecone’s moat is being eroded by two specific forces. pgvectorscale hit 471 QPS at 99% recall on 50M vectors in 2025, which is roughly the workload size where most teams used to migrate from Postgres to Pinecone. Qdrant Cloud is selling the same managed-vector-DB pitch at roughly half the price per query. The serverless rewrite is the architecture buying Pinecone time. The open question is whether Pinecone’s managed-experience advantage and the Inference and Assistant products are enough to keep the next cohort of engineers from defaulting to “just use Postgres.”
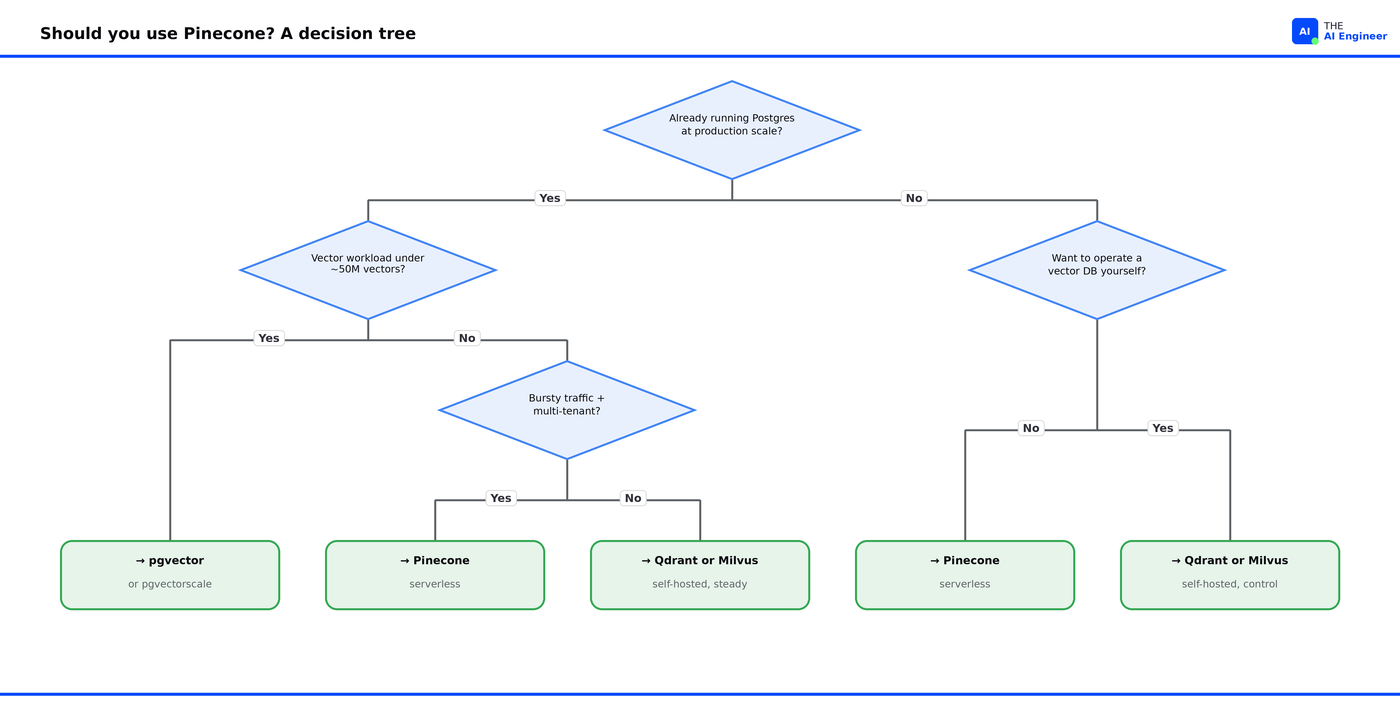
Use Pinecone if: you’re shipping a multi-tenant RAG product with thousands of customers who each need their own vector data, your traffic is bursty (mostly cold with bursts of activity), you don’t have a Postgres-fluent team that wants to operate a database, or you’re moving fast and the cost of any operational surprise is bigger than the cost of the bill.
Skip Pinecone if: you already run Postgres at production scale, your vector workload is under 50M vectors, your traffic is steady (where the pod-style amortization wins), or you’re optimizing for raw cost at large scale and have engineers who will tune Milvus or Qdrant.
The reframe
Pinecone’s product is excellent. The category around it is dissolving. Three years ago vector databases were a category, with a separate product, a separate vendor, and a separate bill. Today they’re sliding toward feature status, embedded inside Postgres, inside data warehouses, inside platforms like Databricks and Snowflake. Pinecone is fighting that gravity with the only managed vector database that has integrated all four serverless decisions. The architecture is genuinely the best in the category. Whether that’s enough depends on whether you think managed convenience is worth a separate vendor when your database can almost do the job.
Anyone running Pinecone serverless at billion-scale, how bad are cold-start latencies in practice? Pinecone’s engineering blog says up to 20 seconds, but I want to hear from teams living with it.
Where to Next?
📖 Go Deeper: Pinecone vs Weaviate vs Qdrant vs Milvus vs Chroma. The benchmarks, the verdict, and which one to actually pick.
🔗 Go Simpler: What are Embeddings? What’s actually in those vectors before they hit the database.
🔀 Go Adjacent: How DoorDash Built Their RAG System What production RAG looks like end-to-end, including the database layer.
Want to break into AI engineering? How to Break Into AI Engineering in 2026 is the full roadmap on getting there.
🔜 Friday: How Anthropic Built Multi-Agent Research. Inside the orchestrator-worker pattern, the token budget that made it shippable, and why most multi-agent systems fall apart in production.
How Pinecone hit $14M revenue and 4K customers in 2025 (Dec. 2025) https://getlatka.com/companies/pinecone.io ↩ ↩
Top 10 Vector Databases in 2026 (Mar. 2026)
Vector Database Comparison 2026 (Apr. 2026)