

What are Embeddings?
The invisible math that makes AI actually understand what you mean

The Pain
You build a customer support chatbot. You load it with 3,000 help articles. A user types “I got charged twice but only ordered one thing.” The chatbot searches your knowledge base, finds nothing relevant, and responds with a generic apology.
The answer was right there. In an article called “Duplicate Transaction Resolution Guide.” Same problem, completely different vocabulary. The user said “charged twice.” The article says “duplicate transaction.” Your search matched words. The customer was describing a situation. (I’ve shipped this exact bug. Twice.)
Even with stemming, synonym dictionaries, and fuzzy matching, no keyword engine connects “charged twice but only ordered one thing” to “duplicate transaction resolution.” The gap is conceptual, not lexical. And it’s the reason every AI search system, every RAG pipeline, and every recommendation engine on the planet now depends on the same core technology.
TL;DR
Embeddings are GPS coordinates for meaning. They convert text (or images, or code) into a list of numbers that represent where that content sits in a “meaning space.” Similar ideas get similar coordinates, even if they share zero words.
They solve the vocabulary mismatch problem. “Charged twice but only ordered one thing” and “duplicate transaction resolution” describe the same situation. Keyword search can’t see that. Embeddings can.
The mechanism: An embedding model reads your text and outputs a vector, typically 768 to 3,072 numbers. These vectors get stored in a vector database for fast retrieval.
Everyone uses them. Spotify maps every artist, track, and listener into a shared embedding space for recommendations. DoorDash embeds support documents for their RAG-powered customer service. LinkedIn embeds 950M+ member profiles for job matching.
The counterintuitive part: Bigger embeddings aren’t always better. Teams routinely find that smaller models (512 dimensions) deliver comparable retrieval quality to larger ones (3,072 dimensions) on their production data, at a fraction of the cost and latency.
Let’s get into it.
Before Embeddings, There Was Keyword Search
Think of keyword search like a GPS system that only understands exact street addresses. You type in “123 Main Street” and it finds 123 Main Street. Great. But type in “the coffee shop on the corner of Main and 2nd” and it returns nothing, because that string doesn’t match any address in the database.
That’s how traditional search works with text. It matches strings. And let’s give it credit: the techniques have gotten sophisticated over the decades. BM25 considers word rarity and document length. Elasticsearch adds stemming (”running” matches “run”), synonym expansion, and fuzzy matching to handle typos.
For a lot of use cases, this is plenty. If someone searches for “Python 3.12 release notes,” keyword search nails it. The words in the query are the words in the document. When query vocabulary and document vocabulary overlap, keyword search is fast, cheap, and battle-tested.
📗 Prerequisite: We covered how this fits into the bigger picture in What is RAG?. Quick version: RAG = retrieve relevant documents, then feed them to an LLM. Embeddings are what make the retrieval step understand meaning instead of just matching keywords.
Why Keyword Search Breaks Down
The moment users start describing situations rather than naming features, keyword search hits a wall.
Your knowledge base has these three articles:
Document A: "Duplicate Transaction Resolution Guide"
Document B: "How to Issue a Partial Refund"
Document C: "Chargeback Dispute Process"
A customer asks: “I got charged twice but only ordered one thing”
Even with BM25 and synonym expansion, the system struggles. “Charged” partially matches Document C’s “chargeback,” but the customer’s real problem is a duplicate charge, not a dispute. Document A is the right answer, but “charged twice” and “duplicate transaction” share almost no vocabulary. The search engine ranks Document C higher because of the word overlap, and Document A gets buried.
Now multiply this across every way customers describe the same problem:
“my card was billed two times” → should match Document A
“I need some of my money back” → should match Document B
“the store won’t fix my bill” → should match Document C
Each query uses completely different words than the document titles, but the intent is clear to any human who reads them. Keyword search can’t bridge the gap, because it doesn’t understand meaning. It only understands strings.

This is the vocabulary mismatch problem at scale. And it doesn’t just affect support chatbots. It affects every system that needs to match user intent to content: search engines, recommendation engines, RAG pipelines, classification systems, and duplicate detection.
⚠️ Confusion Alert: “Embeddings” and “vectors” are often used interchangeably, but they’re not the same thing. A vector is just a list of numbers. An embedding is a vector with a specific property: the numbers encode meaning, trained by a model to place similar concepts near each other. Not all vectors are embeddings. All embeddings are vectors.
How Embeddings Actually Work
Embeddings exist because machines need a way to represent meaning as numbers. Text is messy, ambiguous, and infinite. Numbers are structured, comparable, and searchable. Here's how the translation works.
Remember the GPS analogy? A GPS coordinate is just two numbers, but those two numbers tell you exactly where something is on the planet, and how close it is to anything else. Embeddings do the same thing for text. They give every piece of text a set of coordinates in “meaning space.” Instead of 2 dimensions (latitude and longitude), embedding models use 768 to 3,072 dimensions.
Here’s where the analogy gets a caveat. With GPS, each dimension is interpretable: latitude = north-south, longitude = east-west. Embeddings don’t work that way. No single dimension maps to a human concept like “topic” or “formality.” The meaning is distributed across all dimensions at once. You can’t look at dimension 47 and say “that’s the tone dimension.” But the analogy still holds for the part that matters most: things that are close in meaning get close coordinates, and things that are different end up far apart.
So how does the model learn which things are “close”? Through contrastive training. You feed the model millions of text pairs: some that are semantically similar (a question and its answer, a query and its matching document) and some that aren’t. Over time, it learns to produce vectors that place similar texts near each other and dissimilar texts far apart. No one hand-engineers the dimensions. The model discovers the geometry of meaning from data. (This is the part that still feels a little magical, even after you’ve done it a dozen times.)
The result: “charged twice but only ordered one thing” and “Duplicate Transaction Resolution Guide” end up close together in this space. “Best pizza in Brooklyn” ends up far away.
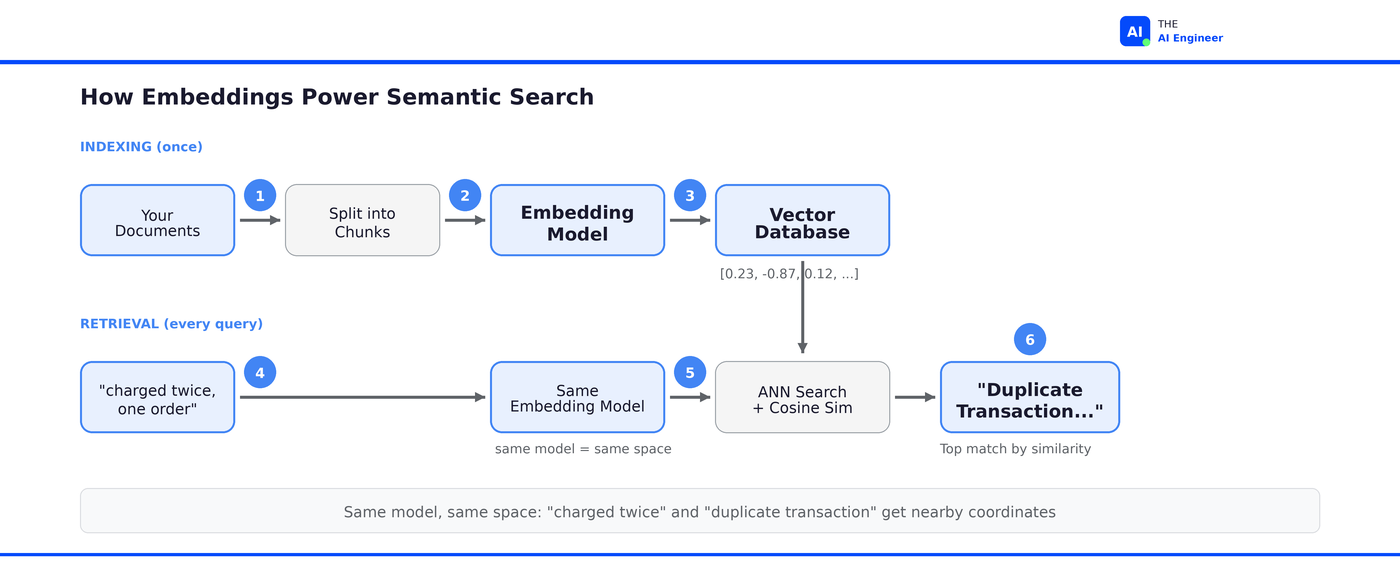
Here’s the step-by-step:
Step 1: Chunk your documents. You can’t embed an entire 200-page manual as one vector: the meaning gets diluted. So you split documents into chunks, typically 256 to 512 tokens each. Each chunk should contain a complete thought.
Step 2: Run each chunk through an embedding model. The model reads the text and outputs a vector. Popular choices in 2026: OpenAI’s text-embedding-3-small (1,536 dimensions, $0.02/million tokens) is the default I’d reach for on a new project. text-embedding-3-large (3,072 dimensions, $0.13/million tokens) when you need maximum recall and don’t mind the storage cost. Open-source alternatives: Google’s EmbeddingGemma (308M parameters, runs on-device in under 200MB of RAM) and Qwen3-Embedding for multilingual tasks. More on model choice in the tradeoffs section, but the short version: pick one and benchmark on your data. Don’t overthink it.
Step 3: Store vectors in a vector database. The vectors go into a specialized database (Pinecone, Qdrant, Milvus, or pgvector if you want to keep things simple). These databases are optimized for one operation: given a query vector, find the nearest neighbors fast.
Step 4: When a user queries, embed the query too. “I got charged twice but only ordered one thing” becomes a vector using the same model. Now you have two things in the same coordinate space: the query and all your document chunks.
Step 5: Find the approximate nearest neighbors. This is the whole reason vector databases exist. They don’t compare your query against every stored vector (that would be O(n) and impossibly slow at scale). Instead, they use approximate nearest neighbor (ANN) algorithms like HNSW or IVF to narrow the search to a small subset of candidates. The tradeoff: you might miss the absolute closest vector, but you find very close ones in milliseconds instead of minutes. The standard distance metric is cosine similarity, which measures the angle between two vectors.
Step 6: Return the top results. The chunks closest to the query vector are the ones most semantically similar. “Duplicate Transaction Resolution Guide” is now the top result for “charged twice but only ordered one thing”, even though they share almost no keywords.
Here’s what this looks like in code:
from openai import OpenAI
client = OpenAI()
# Embed a document chunk
doc_embedding = client.embeddings.create(
input="Duplicate Transaction Resolution Guide: If a customer reports being charged multiple times...",
model="text-embedding-3-small"
).data[0].embedding
# Embed a query
query_embedding = client.embeddings.create(
input="I got charged twice but only ordered one thing",
model="text-embedding-3-small"
).data[0].embedding
# Compute cosine similarity
import numpy as np
similarity = np.dot(doc_embedding, query_embedding) / (
np.linalg.norm(doc_embedding) * np.linalg.norm(query_embedding)
)
print(f"Similarity: {similarity:.4f}")
# Your number will vary. Higher = more similar. Typical "good match" range: 0.75-0.90
Note: this code makes two round-trip API calls, which means ~200-500ms per call. That’s fine for understanding how embeddings work. In production, teams self-host embedding models or use local inference to hit the latency targets that matter: 10-50ms for query embedding, 10-100ms for vector search, 50-200ms end-to-end.1
Who’s Actually Building With This
Embeddings aren’t a research curiosity. They’re load-bearing infrastructure at every major tech company, and not just for recommendations.
Spotify doesn’t embed each listener once. They embed them at three timescales: ~6 months of listening history captures core interests, ~1 month captures mid-term shifts, and ~1 week captures fresh intent. These get fused through an autoencoder into a single user embedding that downstream systems can query.2
But here’s the engineering insight that surprised me: when training these embeddings, separating skipped tracks from played tracks was “clearly beneficial” to model performance. Your skips are a stronger signal than your plays. The embedding model learns more about your taste from what you reject than from what you passively listen to. This is how Discover Weekly can surface a song you’ve never heard from a genre you’ve barely explored: the model knows, from your skip patterns, exactly where the boundary of your taste sits.3
DoorDash uses embeddings at the core of their Dasher support chatbot. When a delivery driver hits a problem mid-route, the system embeds their message, retrieves the most relevant knowledge base articles via vector search, and feeds them to an LLM to generate a grounded response. Standard RAG pattern, but here’s where it got interesting: the retrieval worked, but the LLM kept hallucinating anyway. It would generate responses that sounded natural and legitimate but were actually based on outdated DoorDash info the model had absorbed from Reddit and Quora during pre-training, not from the retrieved documents. So DoorDash built a two-tier guardrail system. Tier one: a cheap, in-house semantic similarity check between the LLM’s response and the retrieved articles. If the response aligns, it ships. If not, tier two: a full LLM-based evaluator checks for grounding, coherence, and policy compliance. They initially built a single sophisticated guardrail, but the latency and token cost made it unusable in production. The two-tier approach was the engineering compromise. Result: 90% reduction in hallucinations, 99% reduction in severe compliance violations.4
Pinterest tried the obvious approach first: one embedding per user. It didn’t work. When someone is interested in home renovation AND Japanese cooking AND vintage cars, a single embedding averages those interests into mush, and the recommendations become generically mediocre. Their PinnerSage system fixes this by creating multiple embeddings per user, one per interest cluster. At retrieval time, the system selects the most relevant cluster instead of querying one blurred-together vector. A/B tests showed significant gains in user engagement across their 2B+ Pin catalog. The lesson: the “standard” single-embedding approach breaks down the moment user behavior is multi-faceted, which is always.5
Three companies, three different use cases (recommendations, RAG-powered support, personalization), same core technology. And notice the pattern: none of them stopped at “embed and retrieve.” Spotify discovered that what you skip teaches the model more than what you play. DoorDash found that good retrieval doesn’t prevent bad generation. Pinterest learned that one embedding per user produces mediocre recommendations. The embedding is the starting point. The engineering is everything you build on top.
What Can Go Wrong (and What’s Overhyped)
Embeddings are real and foundational. But they come with tradeoffs that the “build a RAG app in 10 minutes” tutorials conveniently skip.
The dimensionality trap. Higher dimensions capture more nuance, but at a cost. A billion documents at 3,072 dimensions in float32 requires roughly 12TB of storage before indexing overhead. The same dataset at 512 dimensions takes 2TB.6
Many teams find that the smaller model delivers comparable retrieval quality on their production queries, even when the larger model scores higher on MTEB benchmarks. The benchmarks test academic datasets. Your users don’t search like academic datasets.
Embedding drift. Your embedding model was trained on a snapshot of language. But language shifts, your product vocabulary changes, and new concepts emerge. The embeddings you generated six months ago may no longer align well with queries from today. Production teams need to re-embed their corpus periodically, and that’s an expensive batch job that scales linearly with your data size. (I’ve seen teams discover this the hard way when retrieval quality slowly degrades and nobody can figure out why.)
The cold start problem. Embeddings are only as good as the training data the model saw. A new product category, a new type of support ticket, or a niche domain with specialized vocabulary will produce poor embeddings because the model never learned the distance relationships in that domain. The fix is fine-tuning on your domain data, or choosing a model trained on a corpus closer to yours. There’s no passive adaptation: the model won’t get better at your domain just because you embed more of your documents through it.
The mathematical ceiling. This is the one most people don’t know about. In August 2025, Google DeepMind published a paper proving that single-vector embeddings have a fundamental geometric limit: for any given embedding dimension, there are combinations of documents that cannot be retrieved, no matter how good the model is. They built a test called LIMIT with trivially simple queries like “Who likes apples?” matched against “Jon likes apples.” State-of-the-art models scored under 20% recall@100. The limitation isn’t training data or model size. It’s the single-vector paradigm itself. More dimensions help, but the combinatorial space grows faster than any practical dimension count can cover. This is why production systems don’t stop at embeddings: they layer rerankers, multi-vector models like ColBERT, and hybrid retrieval on top.7
The honest take
Embeddings are not overhyped. They’re genuinely one of the most important concepts in AI engineering. But two things around them are. First, model selection. Engineers spend days comparing OpenAI vs Cohere vs Voyage vs open-source on MTEB benchmarks, when the real differentiator is whether you evaluate on your own data. There’s no single “best” embedding. Second, the keyword-vs-semantic binary. Most production systems don’t choose. They use both. Hybrid search combines BM25 for exact-match queries (”error code 4012”) with embeddings for conceptual queries (”app crashes when I try to pay”). The teams that ship reliable search combine both retrieval methods and let a reranker sort out the final ordering.
The One Thing to Remember
Embeddings don’t teach AI to understand language. They teach AI that language has geography. That “charged twice” and “duplicate transaction” live in the same neighborhood, even though they look nothing alike. But geography has limits. A map can tell you two cities are close, but it can’t tell you which floor of a building you’re on. Embeddings have the same constraint: they’re powerful enough to make search feel like magic, and too lossy to be the whole answer. The teams that know this build systems on top. The teams that don’t wonder why retrieval keeps failing on queries that seem simple.
Where to Next?
🔬 Go Deeper: The Vector Database Showdown: Pinecone vs Qdrant vs Milvus. You’ve got the vectors. Now where do you store them?
📗 Prerequisite: What is RAG?. Embeddings are what make the retrieval step understand meaning. If you haven’t read the RAG explainer yet, start there.
🔗 Related: What is an AI Agent?. Agents use embeddings for memory and retrieval, turning semantic search into a tool they can call autonomously. If you’re building agents, embeddings are the foundation of how they remember and find things.
What’s the hardest part of working with embeddings in your stack? Hit reply: I read every response and the best questions become future issues.
Google’s Sahil Dua gave a talk at QCon London 2025 on building embedding models at Gemini scale. Key insight: the production gap between “embed a query” and “serve results” is where most teams underinvest. InfoQ Talk
Generalized User Representations for Large-Scale Recommendations, Spotify Research (September 2025).
Contextual and Sequential User Embeddings for Music Recommendation, Spotify Research (RecSys 2020).
Path to High-Quality LLM-Based Dasher Support Automation, DoorDash Engineering (April 2025).
Embedding Infrastructure at Scale, Introl Blog (December 2025).
On the Theoretical Limitations of Embedding-Based Retrieval, Weller et al., Google DeepMind (August 2025).