

What Does NVIDIA Actually Do?
$130 billion in revenue. The chip is the least interesting part

The Pain
NVIDIA is a $4.5 trillion company. Their CEO is a leather-jacket-wearing celebrity who keynotes in front of stadium crowds. Your LinkedIn feed has at least one “NVIDIA is eating the world” post per day. Every AI company on earth is either buying their chips, on a waitlist for their chips, or building alternatives to avoid depending on their chips.
And yet, if you asked most engineers “what does NVIDIA actually do beyond making GPUs,” the answer gets vague fast. Something about CUDA? Data centers? Gaming?
Here’s the thing: NVIDIA stopped being a GPU company years ago. The GPU is one layer of a five-layer platform that controls nearly the entire AI infrastructure stack. Think of it like a toll road system: NVIDIA doesn’t just build the highway. They own the on-ramps, the interchanges, and the navigation system every driver uses. Competitors can build a faster stretch of road, but nobody else owns the system. Understanding what NVIDIA actually built, and where the cracks are forming, is the difference between making informed infrastructure decisions and blindly following whatever your cloud provider defaults to.
TL;DR
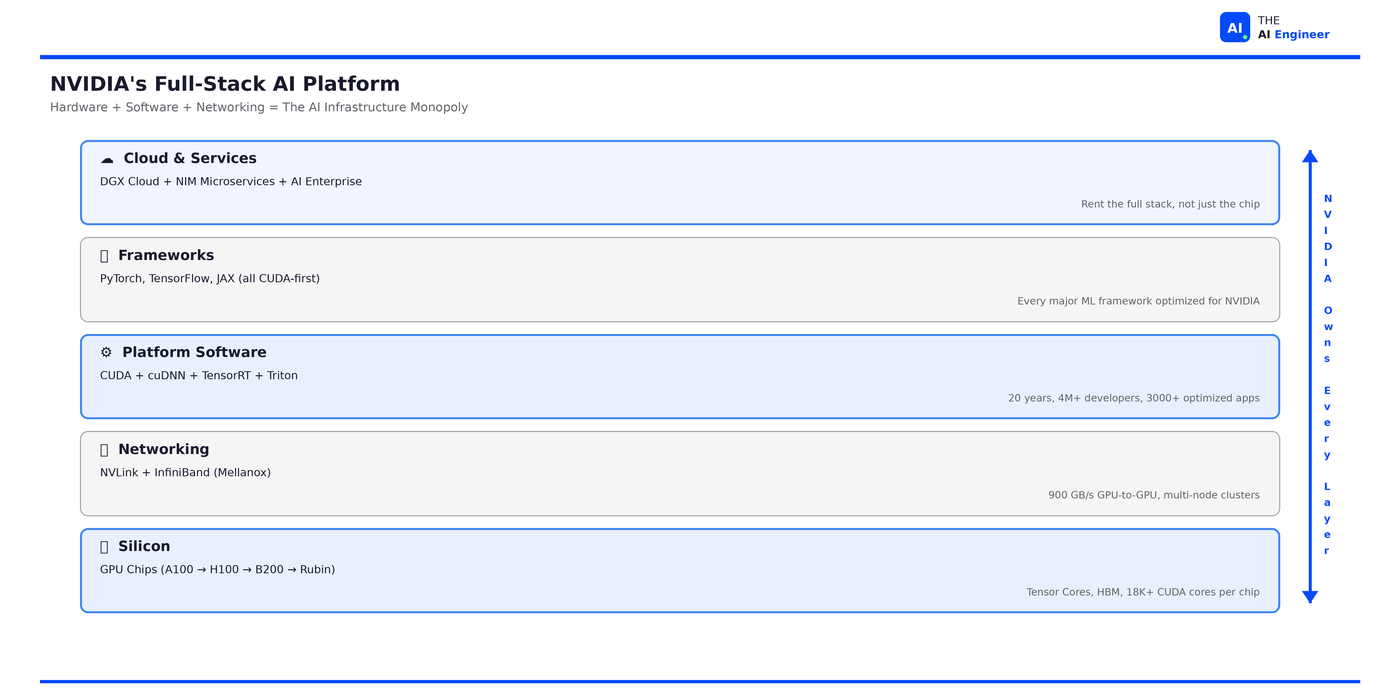
NVIDIA is a full-stack AI infrastructure company that happens to make GPUs. They own five layers: silicon (chips), networking (NVLink/InfiniBand), platform software (CUDA), framework integration (PyTorch/TensorFlow/JAX), and cloud services (DGX Cloud). No competitor owns more than two.
The real moat isn’t the hardware. It’s CUDA. A software ecosystem with 4+ million developers, 3,000+ optimized applications, built over nearly 20 years. Switching away from CUDA means rewriting optimization code, retraining engineers, and revalidating pipelines. Most teams won’t do it.
NVIDIA generated $130.5 billion in revenue in fiscal 2025, up 114% year-over-year. Data center revenue alone was $115.2 billion, representing 91% of total company revenue. This is no longer a gaming company.
Their strategy is deliberate self-cannibalization. Jensen Huang ships a new architecture annually (Hopper → Blackwell → Rubin), making last year’s flagship obsolete on purpose. He calls himself “the chief revenue destroyer.”
The counterintuitive part: NVIDIA’s biggest customers are also its biggest threats. Microsoft, Google, Amazon, and Meta each spend tens of billions on NVIDIA hardware while simultaneously building custom silicon to reduce that dependency.
Let’s get into it.
Before NVIDIA: Understanding the AI Hardware Landscape
Before we evaluate NVIDIA specifically, let’s establish what the AI hardware market actually looks like.
🔗 Prerequisite: We covered GPUs from first principles in What is a GPU? Quick version: GPUs run thousands of simple operations in parallel, which is exactly what neural network training needs. A CPU processes sequentially. A GPU processes simultaneously.
The AI hardware market has three tiers of players:
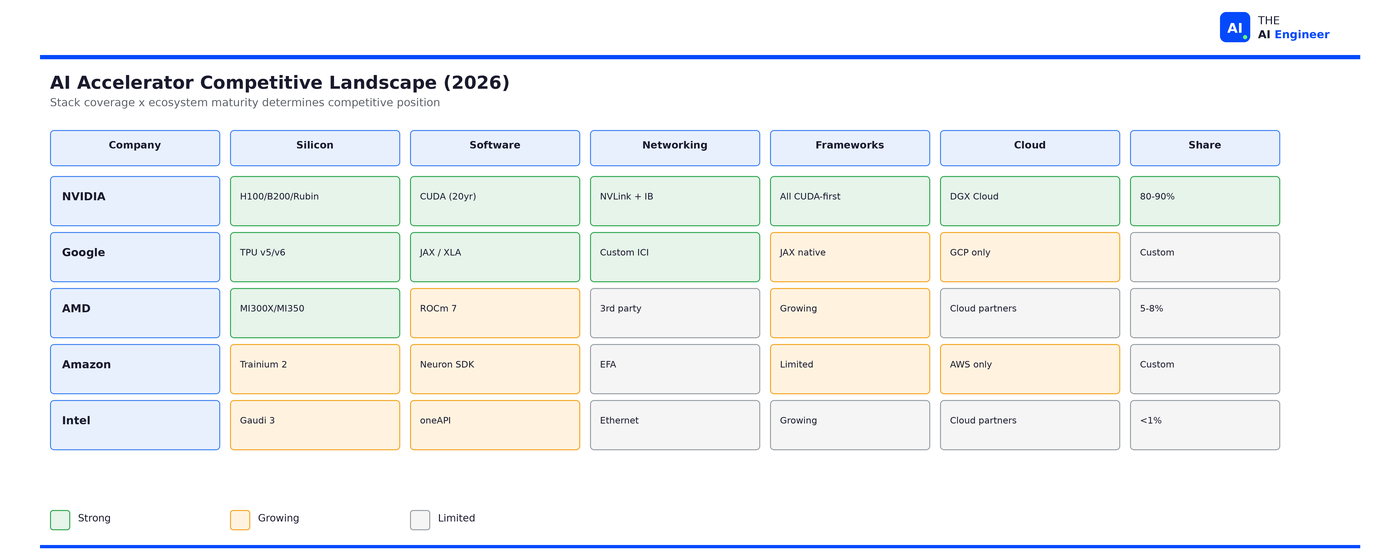
Merchant silicon refers to chips you can buy on the open market. NVIDIA dominates this with roughly 80-90% revenue share. AMD is the only meaningful competitor here, with the MI300X and upcoming MI350 targeting the same workloads. Intel’s AI accelerator efforts have largely stalled.
Custom silicon refers to chips built by companies for their own use. Google’s TPUs, Amazon’s Trainium, Microsoft’s Maia, and Meta’s MTIA all fall here. These chips are designed to reduce dependence on NVIDIA, but they’re only available within each company’s own ecosystem.
Specialized accelerators include startups like Cerebras (wafer-scale chips), Groq (deterministic inference), and SambaNova. Interesting technology, but none have achieved meaningful market share against NVIDIA’s ecosystem.
NVIDIA’s position is unique because it doesn’t just compete at the chip level. It competes across the entire stack. If you’re choosing AI infrastructure, this taxonomy matters for one reason: merchant silicon is portable across clouds. Custom silicon locks you into one provider. Specialized accelerators are a bet on a startup. NVIDIA is the only merchant option that spans all five layers.
The Evolution: From Gaming to AI Infrastructure
NVIDIA was founded in 1993 as a graphics company. For its first decade, “GPU” meant exactly what the name says: a processor for rendering graphics in video games. That market still exists (NVIDIA’s GeForce line generated $12.9 billion in gaming revenue in FY2025), but it’s now a sideshow.
The pivotal moment was 2006, when NVIDIA released CUDA (Compute Unified Device Architecture). CUDA turned a graphics processor into a general-purpose parallel computing platform. For the first time, researchers could write code that ran on GPU hardware without thinking about graphics at all.
For six years, CUDA was a niche tool used mostly by physicists and computational scientists. Then, in September 2012, a team from the University of Toronto submitted a deep neural network called AlexNet to the ImageNet competition, an annual benchmark where teams compete to classify millions of images into 1,000 categories. AlexNet achieved a 15.3% error rate, crushing the second-place entry at 26.2%. That second-place entry used traditional computer vision techniques that researchers had been refining for decades. AlexNet ran on two NVIDIA GTX 580 GPUs using CUDA.1
That single result triggered a paradigm shift. Suddenly every AI researcher needed GPUs, and they needed CUDA, because that’s what AlexNet used, and that’s what TensorFlow and PyTorch were being optimized for. NVIDIA went from “the gaming GPU company” to “the AI infrastructure company” in under five years. Revenue followed: data center revenue went from roughly $3 billion in 2020 to $47.5 billion in FY2024 to $115.2 billion in FY2025:2 38x in five years.
But the road wasn’t smooth. In 2020, NVIDIA attempted to acquire ARM Holdings for $40 billion, a deal that would have given them control of the CPU architecture powering nearly every mobile device and a growing share of data center servers. Regulators in the US, EU, and UK blocked it on antitrust grounds. The deal collapsed in early 2022. It was NVIDIA’s biggest strategic failure of the decade, and it exposed a pattern that would recur: every time NVIDIA tries to expand beyond its current stack, external forces push back. Regulators blocked the ARM deal. Hyperscalers responded to GPU lock-in by building their own silicon. Open-source projects attacked the CUDA moat. NVIDIA’s dominance invites its own opposition.
The Architecture: NVIDIA’s Five-Layer Platform
Here’s what makes NVIDIA different from every competitor: they own the full stack. Let’s walk each layer.
Layer 1: Silicon (The Chips)
The foundation. NVIDIA’s data center GPU line has followed a rapid cadence: Volta (2017) → Ampere/A100 (2020) → Hopper/H100 (2022) → Blackwell/B200 (2024) → Rubin (2026).
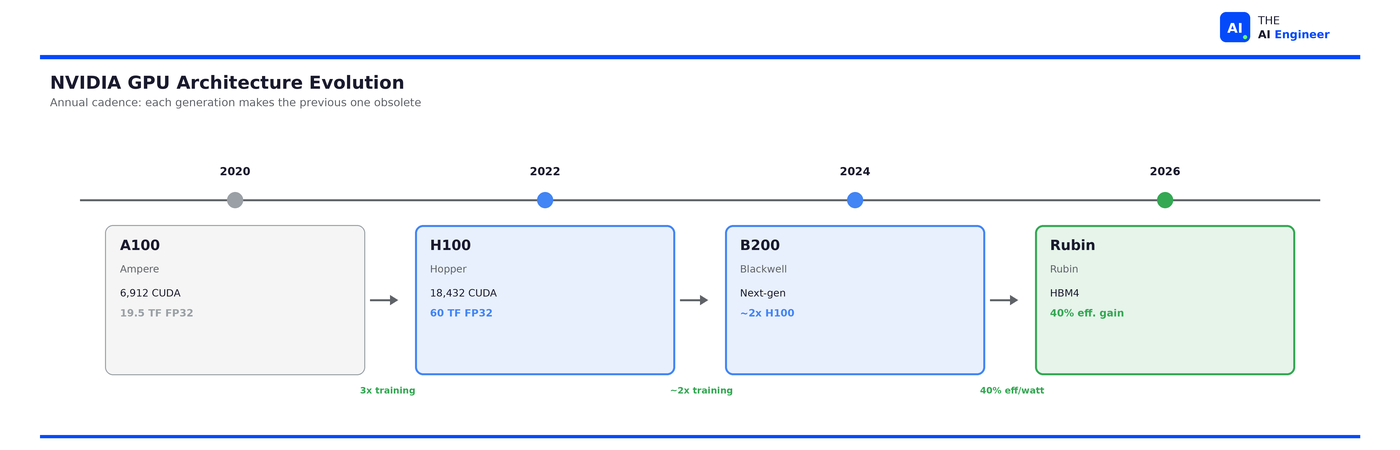
Each generation isn’t incremental. The H100 delivered 9x faster AI training and 30x faster inference compared to the A100. Blackwell promises another 2x over Hopper on training and 5x on inference. Jensen Huang’s annual cadence (announced at GTC 2024) means every chip is obsolete within 12-18 months. This is intentional. If NVIDIA doesn’t cannibalize its own products, someone else will.
The economics are staggering. An H100 SXM costs approximately $3,320 to manufacture and sells for around $25,000-40,000. That’s an 88% gross margin on the hardware alone. NVIDIA’s overall gross margin sits around 73-75%, making it one of the most profitable hardware companies in history.3
Layer 2: Networking (NVLink + InfiniBand)
Training frontier models requires thousands of GPUs working in concert. The bottleneck isn’t individual GPU speed: it’s how fast data moves between GPUs.
NVIDIA solved this by acquiring Mellanox in 2019 for $6.9 billion. NVLink provides 900 GB/s of GPU-to-GPU bandwidth within a node (4th generation on H100). InfiniBand provides high-speed networking between nodes in a cluster. Together, they mean NVIDIA doesn’t just sell you chips. They sell you the interconnect fabric that makes multi-thousand-GPU clusters actually work.
To put the gap in perspective: standard data center Ethernet runs at 100-400 Gb/s. NVLink runs at 7,200 Gb/s. During a training run like GPT-4 across 25,000 GPUs, every GPU needs to synchronize gradients after each training step. If the interconnect is slow, thousands of GPUs sit idle waiting for data from their neighbors. At $2-3/hour per GPU, idle time is expensive. NVIDIA’s networking layer doesn’t just improve performance. It determines whether large-scale training is economically viable at all.
This is a layer no competitor fully replicates. Competing chip vendors have competitive silicon but rely on third-party networking. Google’s TPUs have custom interconnects but only within Google Cloud.
Layer 3: Platform Software (CUDA)
This is the moat. The on-ramps that every driver in AI has been using for so long that nobody remembers how to take a different route.
CUDA launched in 2006 and has been continuously developed for nearly 20 years. The ecosystem now includes cuDNN (deep learning primitives), cuBLAS (linear algebra), TensorRT (inference optimization), Triton Inference Server (model serving), and NCCL (multi-GPU communication), among hundreds of other libraries.
The numbers tell the story: 4+ million developers, 3,000+ GPU-accelerated applications, 40,000+ companies using CUDA, and over 450 million cumulative CUDA downloads. Universities teach CUDA. Research papers benchmark on CUDA. Job postings require CUDA experience.
Here’s what the lock-in looks like from an engineer’s perspective:
# NVIDIA: works everywhere, every tutorial assumes this
model = model.to('cuda')
trainer.train() # cuDNN, cuBLAS, NCCL all fire automatically
# ROCm (alternative stack): same API call, different world underneath
model = model.to('cuda') # Yes, ROCm reuses the same 'cuda' device string via HIP
trainer.train() # But: check PyTorch version, ROCm version, driver version, kernel compatibility
Your code looks identical on CUDA and ROCm. The results aren't. The same training job runs 10-30% slower on ROCm because the libraries underneath haven't had 20 years of optimization. And when something breaks, the Stack Overflow answer doesn't exist yet.
⚠️ Confusion Alert: “CUDA is just a programming language” is a common misunderstanding. CUDA is a full parallel computing platform: compiler, runtime, libraries, profiling tools, and a massive ecosystem of pre-optimized code. The 'language' is the smallest part of it.
Layer 4: Framework Integration
Layers 1 through 3 are NVIDIA’s own products: their chips, their networking, their software. Layer 4 is different. This is NVIDIA inside everyone else’s software.
NVIDIA has engineers contributing directly to PyTorch, TensorFlow, and JAX. They don’t wait for framework teams to add support for new hardware features. When NVIDIA shipped FP8 support and the Transformer Engine with the H100, their own engineers wrote the PyTorch and TensorFlow integrations and submitted them. By the time the framework releases, the NVIDIA fast path is already baked in.
They also ship NGC (NVIDIA GPU Cloud): pre-validated containers that bundle a specific framework version, a specific driver version, and a specific library version, all tested together. Anyone who’s spent a day debugging a CUDA/PyTorch/driver version mismatch understands why this matters.
The result: Layer 3 means NVIDIA built the tools. Layer 4 means everyone else’s tools are wired to depend on them. This creates a compounding flywheel. Framework developers optimize for NVIDIA because that’s where the users are. Users stay on NVIDIA because that’s where the optimization is. The flywheel has been spinning for a decade, and it’s the reason “works on CUDA” is the default assumption in every ML paper, every tutorial, and every production deployment guide.
Layer 5: Cloud and Services
Layers 1 through 4 make NVIDIA’s hardware indispensable. Layer 5 is the move to make it invisible. Instead of selling you chips and letting you figure out the rest, NVIDIA now sells the entire stack as a service.
DGX Cloud lets enterprises rent NVIDIA’s full platform (silicon, networking, CUDA, frameworks) through cloud providers without managing any of it. NIM (NVIDIA Inference Microservices) goes further: pre-optimized model containers where the engineer interacts with a Docker pull and an API endpoint. A team deploying Llama 3 70B can go from zero to production-ready inference in minutes. No CUDA kernel tuning. No TensorRT configuration. No multi-GPU orchestration. Everything underneath, five layers deep, is NVIDIA.
This creates an unusual dynamic: NVIDIA is now competing with its own customers. AWS, Azure, and GCP all resell NVIDIA hardware. DGX Cloud lets enterprises bypass them and rent directly from NVIDIA’s stack. The cloud providers tolerate this because they can’t afford to not carry NVIDIA hardware. NVIDIA tolerates the channel conflict because DGX Cloud captures margin at every layer, not just silicon.
I’ve provisioned H100 instances on three different cloud providers, and the CUDA setup was identical on all three. That uniformity is the lock-in at its most frictionless.
But here’s what happens when NIM doesn’t have a pre-optimized container for your model: you’re back to writing custom TensorRT profiles, tuning kernel launch configurations, and debugging multi-GPU memory allocation by hand. The easy path only works when you stay on NVIDIA’s road. Step off it, and the complexity of the four layers underneath hits you all at once.
How NVIDIA Got Here: Three Engineering Bets
Decision 1: Software-first, hardware-second
The decision: Invest billions in a free software platform (CUDA) that only works on NVIDIA hardware, rather than competing purely on chip specs.
The context: In 2006, GPUs were commodity graphics hardware. NVIDIA’s bet was that making GPUs programmable for general computation would create demand that didn’t yet exist. There was no AI training market. There was no CUDA developer community. The entire investment was a forward bet on a use case that hadn’t materialized.
The tradeoff: Massive R&D spend on software ($12.9 billion in R&D in FY2025) with no direct software revenue. CUDA is free. The entire investment pays off through hardware sales.
The limitations: CUDA only works on NVIDIA hardware. This means NVIDIA has zero software revenue diversification. If a team finds a way to get equivalent performance on non-NVIDIA hardware (via Triton, ROCm, or a future abstraction layer), CUDA’s value proposition collapses. The moat is wide but conditional: it depends on the performance gap remaining meaningful.
The result: AMD’s MI300X has roughly 32% more raw compute on some benchmarks, but CUDA’s software maturity delivers 10-30% better real-world performance on most workloads. The ecosystem lock-in means NVIDIA’s inferior hardware specs (on paper) still win in practice. And by 2025, switching away doesn’t just mean rewriting code. It means retraining an entire workforce. Universities teach CUDA. Job postings require CUDA. The ecosystem became the industry’s muscle memory.
My take: This is the single best strategic decision in semiconductor history. CUDA is free. The entire $12.9 billion annual R&D investment pays for itself because teams that use CUDA have to buy NVIDIA hardware. But that equation only holds as long as CUDA delivers meaningfully better performance than the alternatives. ROCm and Triton are closing that gap. If they reach parity in 2-3 years, NVIDIA is left spending billions maintaining a free product that no longer forces hardware purchases. The moat becomes a cost center.
Decision 2: Annual self-cannibalization
The decision: Ship a new GPU architecture every year, making the previous generation’s flagship obsolete.
The context: Historically, semiconductor companies released new architectures every 2-3 years. Jensen Huang accelerated to annual releases starting with GTC 2024, calling the strategy “the rhythm of NVIDIA” and himself “the chief revenue destroyer.”
The tradeoff: Customers who just spent $25,000 per H100 watch their investment depreciate within a year. This creates purchasing hesitation and customer frustration. Cloud providers must plan infrastructure around a moving target.
The limitations: Annual cadence requires near-flawless execution. When Blackwell hit production challenges in 2024, the compressed timeline left almost no buffer. Supply chain delays on a two-year cycle are manageable. On an annual cycle, a six-month slip means the product barely ships before its replacement is announced.
The result: Competitors are always chasing a moving target. By the time the nearest rival ships a competitive answer to the H100, NVIDIA is already shipping Blackwell. By the time anyone benchmarks against Blackwell, Rubin is announced. The cadence advantage is as much about marketing as engineering.
My take: Brilliant for competitive positioning. Punishing for customers. If you’re an infrastructure team, the annual cadence means you should always be 6-12 months behind the bleeding edge: buy the previous generation at a discount, where the software ecosystem is most mature. Let the frontier labs pay the early-adopter tax.
Decision 3: Own the interconnect
The decision: Acquire Mellanox for $6.9 billion (2019), giving NVIDIA control of both computation and communication in GPU clusters.
The context: Multi-GPU training requires moving massive amounts of data between GPUs. Whoever controls that interconnect controls the cluster economics. Before the acquisition, NVIDIA sold chips but relied on third-party networking.
The tradeoff: $6.9 billion is an enormous bet on a single acquisition. NVIDIA committed to owning a layer of the stack that didn’t have obvious synergies with a graphics company. The integration required years of engineering to unify product lines.
The limitations: NVLink only works within NVIDIA systems. If a customer builds a heterogeneous cluster (mixing GPUs from different vendors, for example), NVLink can’t bridge the gap. The networking advantage locks customers deeper into a single-vendor cluster, which is exactly what hyperscalers are trying to escape. At the scale of 100,000+ GPU clusters now being built, alternative networking solutions (Ultra Ethernet Consortium) are gaining traction.
The result: When OpenAI or Meta builds a 10,000+ GPU cluster, the entire system (chips, networking, management software) comes from one vendor. That’s a lock-in most competitors can’t replicate. The Mellanox acquisition may be the most underrated tech acquisition of the decade.
My take: At today’s cluster sizes, this single acquisition is probably worth $50+ billion in lock-in value to NVIDIA. When you control both the compute and the interconnect, switching vendors means rearchitecting the entire cluster, not just swapping GPUs. That’s a moat within a moat. But the Ultra Ethernet Consortium (backed by AMD, Intel, Microsoft, and Meta) is specifically designed to commoditize this layer. If open networking hits 80% of NVLink’s bandwidth by 2028, the Mellanox premium evaporates. For teams building clusters today: NVLink is the right call under 1,000 GPUs. Above that scale, design for networking portability.
The Honest Take
What’s genuinely impressive: No other company in AI infrastructure owns the full stack. The nearest chip competitor has competitive silicon but weak software. Google has excellent custom silicon but it’s walled inside Google Cloud. Amazon’s Trainium is promising but ecosystem-limited. NVIDIA’s five-layer integration means switching any single layer forces you to re-evaluate the others. That’s a moat built on interdependence, not just quality.
What’s under threat: The pattern of dominance breeding resistance, first visible when regulators killed the ARM deal in 2022, is now playing out across every layer of the stack. Hyperscalers responded to GPU lock-in by building custom silicon for internal workloads. Open-source projects attacked the software moat. The 90% revenue share in AI accelerators is projected to settle near 75% by late 2026. NVIDIA’s absolute revenue keeps growing because the market itself is expanding past $200 billion, but every layer of the stack now faces a dedicated challenger.
The CUDA cracks are real, but 2-3 years from mattering for most teams. OpenAI’s Triton compiler, ROCm 7, and Google/Meta’s TorchTPU project are all attacking the software layer. ROCm 7 delivers up to 3.5x better inference than previous versions. Meta is reportedly exploring TPU usage starting in 2026. These are serious efforts underway. But today, for a mid-sized ML team choosing infrastructure, CUDA is still the rational default. The optimization depth, framework maturity, and talent pool are unmatched. If you're choosing infrastructure today, choose NVIDIA. If you're designing infrastructure to last five years, design it so NVIDIA is swappable. Not because NVIDIA is going anywhere, but because your code should outlast your GPUs.
What switching actually costs today: That “6-12 months” number isn’t abstract. A mid-sized ML team migrating off CUDA would need to revalidate every training pipeline against a new driver stack, recompile custom kernels (if any), re-run regression benchmarks across all production models, retrain ops staff on new monitoring and debugging tools, and accept a period of degraded performance while the new stack’s optimization catches up. From what I’ve seen, a team running 5-10 production models should budget 2-3 engineers full-time for 6 months, assuming nothing breaks in unexpected ways. The cost isn’t just engineering hours. It’s the opportunity cost of not shipping new features during the migration. That’s why most teams don’t switch even when the alternative hardware is competitive on paper.
🔍 Deeper Look: SemiAnalysis published a detailed benchmark analysis comparing NVIDIA’s H100 against the leading competitor. Key finding: on MLPerf inference submissions, the H100 achieves up to 4.5x speedup over the A100, while the best competing chip closes to within 10-15% on raw throughput but falls behind on real-world latency once CUDA-optimized libraries (TensorRT, cuDNN) enter the picture. The gap isn’t silicon. It’s software depth.4 https://newsletter.semianalysis.com/
The One Thing to Remember
NVIDIA didn’t build a monopoly by making the fastest chip. They built a toll road system and made sure every on-ramp, interchange, and mile of pavement was theirs. Competitors can build faster chips. But NVIDIA owns the system that makes those chips useful. The chip is the product. The platform is the lock-in. And right now, the entire AI industry is still driving on NVIDIA’s road, because the alternatives aren’t finished yet.
🏗️ Engineering Lesson: If you’re building new AI infrastructure today, design for hardware portability even if you deploy on NVIDIA. Use framework-level abstractions (PyTorch, not raw CUDA kernels). Test on at least one non-NVIDIA backend during development. The switching cost in 2026 is 6-12 months. In 2028, it might be a config change. Build for the world you’re heading toward, not the one you’re in.
Is your team locked into CUDA, designing for portability, or already running on non-NVIDIA hardware? What’s your switching cost estimate? Hit reply, I read every response.
Where to Next?
🔬 Go Deeper: Why is Inference Slow and Expensive? (coming W10) goes inside the GPU to explain the memory bandwidth bottleneck, KV cache growth, and the five techniques that make inference affordable.
📗 Prerequisite: What is a GPU? covers the hardware fundamentals: what parallel processing actually means, CPU vs GPU architecture, and why CUDA cores matter.
🔀 Related: Cursor vs Claude Code shows the application layer: two AI coding tools that run on NVIDIA hardware, and how the GPU constraints shape what they can do in real time.
we MLQ.ai, AI Chips Research Report
NVIDIA Q4 FY2025 Earnings Release
Silicon Analysts, NVIDIA AI Accelerator Market Share 2024-2026
SemiAnalysis, MI300X vs H100 Benchmark Analysis.
“NVIDIA is a full-stack AI infrastructure company that happens to make GPUs”
100%. it’s really interesting to have watched them go from a gpu/ gaming company to this. i don’t think enough people are aware at this fundamental shift in what nvidia and their actual stack is now. great read!
Good breakdown of the NVIDIA stack. The key insight for investors: NVIDIA’s networking layer (InfiniBand/Mellanox) is what makes the 3.6M Blackwell GPU orders actually deployable at scale. But the companies supplying the physical infrastructure underneath — power, cooling, networking hardware — are where the overlooked compounders live. Arista, Vertiv, and Equinix are riding the same GPU wave without the semiconductor valuation premium.