

How Perplexity Built Their Search Engine
The architecture behind 30 million cited answers a day.

🧭 Part 8 of the RAG & Search course
Perplexity answers questions instead of returning links by owning its retrieval end to end: a crawler, an index of hundreds of billions of pages, a hybrid ranking funnel that ends in cross-encoder rerankers, and the Sonar model writing answers with a citation on every sentence and nothing it did not retrieve.
The Pain
Ask a coding assistant for a library and it will hand you a clean install command for a package that does not exist. One 2025 study ran 16 models across 576,000 code samples and found that nearly one in five recommended packages were hallucinated, invented names that looked just like real ones1. Attackers noticed: register the fake name, and the next developer who pastes the suggestion installs whatever you uploaded. The model was fluent and wrong at the same time, and nothing in it could tell the two apart. That is the failure mode of a model answering from memory: it generates a confident answer because that is what it was trained to do.
The older way of answering has the opposite problem. Ask a search engine and it hands you ten blue links. Three of them hold pieces of the answer, the other seven are dead ends, and the reading and stitching are your job. One approach makes things up; the other makes you do the work. An answer engine has to beat both.
TL;DR
Perplexity is an answer engine: ask a question, get a written answer with a footnote on every sentence, drawn from pages it just read. By May 2025 it was fielding around 30 million of those a day2.
The core rule is strict grounding: the model may only say what the search layer retrieved, and must cite it. No supporting source, no claim. If the sources fall short, it is supposed to say so rather than guess.
The stack is built in-house: its own crawler, its own index of hundreds of billions of pages, and a retrieval engine running on Vespa, because that rule only pays off if retrieval is excellent.
Ranking is a funnel. Cheap lexical and embedding scorers skim a vast candidate pool, then expensive cross-encoder rerankers re-read the survivors, all inside a budget of about 100 milliseconds.
Hard questions get decomposed: the Pro Search planner splits a question into sub-queries, retrieves for each, then synthesizes. That loop is what separates an answer engine from one-shot RAG.
Sonar writes the answer: an in-house model fine-tuned from Llama 3.3 70B for factuality, served on Cerebras hardware at 1,200 tokens a second.
Before Perplexity: Answers from Memory
There are two ways to answer a question: recite it from memory, or look it up. Perplexity bet everything on the second.
To see why, start with the first way. A raw large language model answers closed-book, from memory: everything it knows was baked into its weights during training, so when you ask it something it is reciting a compressed memory of the internet as it looked months ago. That works until the question needs a fact that is recent, niche, or simply was not memorized well, and then the model does the worst possible thing. It writes a fluent answer anyway. It is not trained to flag the difference between a fact it verified and a string that is merely statistically plausible, and it will not stop to say “I am unsure.”
The second way is to look it up. Retrieval-augmented generation, or RAG, turns the test into an open-book exam. We covered the full mechanism in What is RAG?, but the one-line version is: before the model writes anything, you run a search, pull the specific passages that bear on the question, and paste them into the prompt. Now the model answers with the notes in front of it. Aravind Srinivas, Perplexity’s CEO, uses exactly that framing: you want a system that learns the way a student does in an open-book exam, with the source material on the desk instead of in their head.
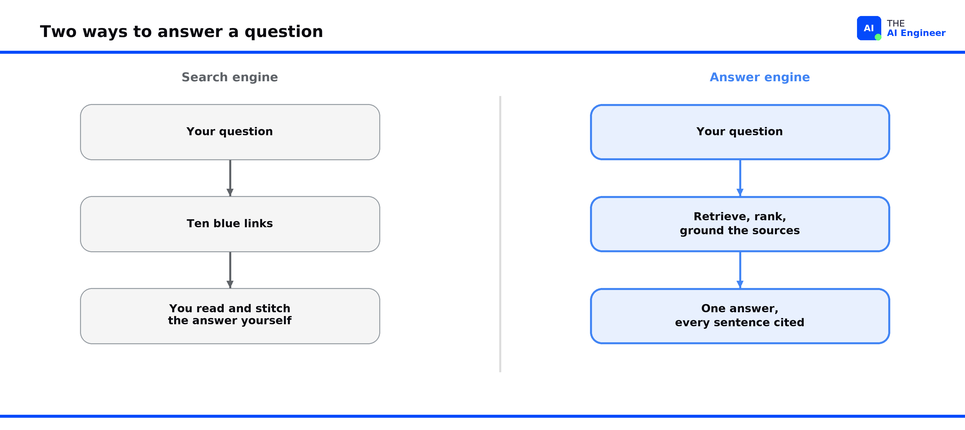
That open-book framing is what the rest of the architecture serves. A search engine on its own gives you links and leaves the reading to you. A model on its own gives you fluent guesses. Combine them well and the answer comes back written and checkable. That is the whole engineering problem Perplexity solved.
Why Perplexity Went In-House
Most RAG treats retrieval as a quick step: call a search API, grab some snippets, move on. Perplexity cannot work that way, because for an answer engine retrieval is the whole product. Srinivas breaks hallucination into four causes, and only one is the model being dim:
the model misreads a good passage;
the index serves a stale or thin snippet;
the search returns documents that do not contain the answer; or
the prompt gets stuffed with so much irrelevant text that the model loses the thread
Three of the four live in retrieval, so fixing the model alone addresses just one, arguably the least decisive, because the other three feed it3.
That is why Perplexity owns its retrieval instead of renting it. In April 2025 it announced it had pulled its search function in-house and rebuilt it on Vespa, an open-source engine that does retrieval, ranking, and machine-learning inference in one serving layer. Underneath it runs PerplexityBot, Perplexity’s own crawler, alongside third-party crawlers it also licenses. The output is a proprietary index that Perplexity describes as covering hundreds of billions of webpages, kept fresh by tens of thousands of index updates every second4.
That last number is worth pausing on, because it is easy to misread. Tens of thousands of updates a second is a write rate, the speed at which new and changed pages enter the index. It is not the query rate. The point of pushing it that high is freshness: when a question is about something that happened an hour ago, the page describing it is already searchable. For a closed-book model, an hour-old event does not exist.
⚠️ Confusion Alert: Perplexity is often dismissed as a wrapper on Google’s index. That is wrong. It runs its own crawler and its own index, the same one it now sells through its Search API. It does also license third-party crawlers, so the honest description is hybrid sourcing over an index it owns, which is a different thing from reselling someone else’s search results.
The Architecture
Perplexity’s pipeline turns a question into a set of cited passages, then has a model write the answer from those passages and nothing else.
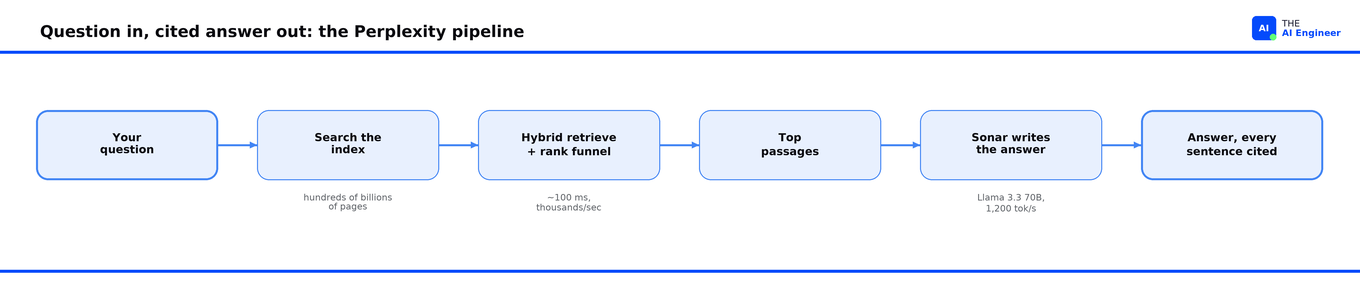
Walk the request end to end. A question comes in. The retrieval layer searches the index and pulls candidate passages; a ranking funnel narrows them from a flood to a handful; the survivors get assembled into a prompt alongside the question; Sonar writes an answer with a footnote on every sentence. The whole round trip takes about a second, roughly 100 milliseconds of retrieval and the rest Sonar writing, which streams as it goes.
The pipeline has three parts: how it indexes, how it ranks, and how it writes.
The index stores meaning alongside words. Every document Perplexity crawls is indexed twice over: once as ordinary text for keyword matching, and once as a set of vector embeddings, numerical coordinates that place a passage by meaning so that “how do I lower my blood sugar” can match a paragraph on glucose management that shares no keywords with the query. We unpacked that idea in What are Embeddings?. The unit of indexing is the sub-document chunk rather than the whole page: Perplexity splits documents into fine-grained pieces and scores each on its own, so one relevant paragraph buried in a long article can surface without dragging the surrounding few thousand words into the prompt. That defuses Srinivas’s fourth hallucination cause, the prompt drowning in noise.
Retrieval is hybrid, and ranking is a funnel. Perplexity does not choose between keyword search and semantic search; it runs both and fuses the scores, the approach we compared in What is Semantic Search?. Keyword matching nails exact terms, names, and error codes; embedding matching catches meaning when the words differ. Then the candidates fall through progressively more expensive stages. Early stages use fast lexical and embedding scorers to cut a huge candidate pool down to a working set. Later stages bring in cross-encoder rerankers, models that read the query and a candidate passage together and judge their fit far more accurately than a vector-distance score can, because the two texts attend to each other directly.
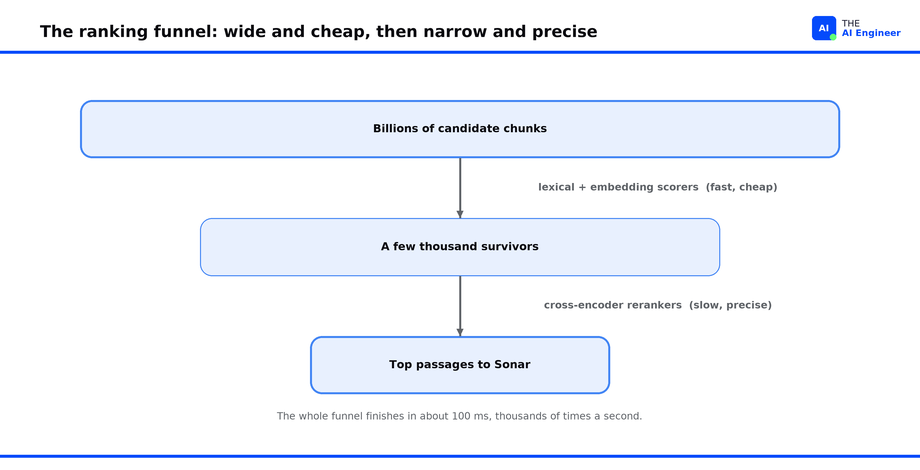
Generation runs on a tight leash. The retrieved passages and the question go to Sonar, Perplexity’s in-house answer model, fine-tuned from Meta’s Llama 3.3 70B for factuality and tight, readable answers. Fine-tuning is the lever we covered in What is Fine-Tuning?: start from a strong open model, then train it further on the narrow job you actually have, which here is “write a concise, sourced answer from these passages.” Sonar attaches a citation to every sentence and draws only from the supplied passages. Serving runs on Cerebras wafer-scale hardware at 1,200 tokens a second, so the answer streams out about as fast as you can read it5.
🔍 Deeper Look: Vespa’s engineering team wrote up the production shape of this system in Perplexity builds AI Search at scale on Vespa.ai, and Perplexity’s own engineers detailed the ranking stages in a companion post. Key line: early stages use lexical and embedding scorers for speed, then “more powerful cross-encoder reranker models” sculpt the final order.
When One Search Is Not Enough
The pipeline above is the single-hop path: one question, one retrieval, one answer. Plenty of real questions do not fit it. Ask “what is the educational background of the founders of LangChain” and a single search fails, because you first have to learn who the founders are before you can look up where each studied.
Perplexity’s Pro Search mode handles that with a planner that separates planning from execution. It first writes a plan, breaking the question into sub-queries. Then it runs them in sequence, and the results of the early steps shape the searches in the later ones: find the founders, then fan out a fresh retrieval for each name. The documents from every step are pooled, ranked, and filtered down to the strongest, and only then does the answer model synthesize across all of them. It is the same retrieve-rank-ground machinery from the single-hop path, wrapped in a loop that runs it several times and feeds each pass into the next6.

This is the part that earns the name “answer engine” over “RAG demo.” One-shot RAG can only answer what a single query surfaces; a planner that decomposes and retrieves iteratively can chase a question whose parts depend on each other. The cost is latency and fragility: every extra hop is another retrieval round and another chance for an early wrong turn to poison the final answer, which is why planning is treated as its own problem rather than bolted onto generation.
The Decisions That Mattered
Three engineering decisions shaped the design. Take them from the most foundational to the most operational.
Decision 1: cite every sentence or refuse. Vanilla RAG adds retrieved context and lets the model write, leaving it free to lean on memorized knowledge. Perplexity tightens the rule: in Srinivas’s words, the model is not supposed to say anything it did not retrieve, and is told to use nothing beyond the retrieved passages. If the sources are thin, the correct output is “I do not have enough information.” The model Perplexity borrows is academic and Wikipedia writing, where every claim needs a citation to a notable source and anything uncited is treated as opinion. The tradeoff is real and they accept it: a strictly grounded engine will sometimes refuse a question a chattier model would answer, because the sources did not cover it. The payoff is that when it does answer, you can click the footnote and check.
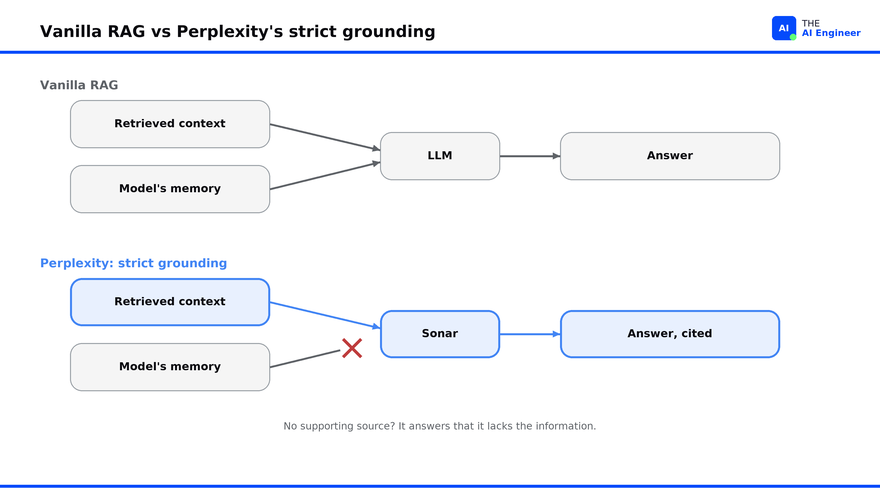
Decision 2: own the index instead of renting search. Renting retrieval means renting your error rate, since three of the four hallucination causes are set by whoever runs the search. So Perplexity built the crawler, the index, and the ranking stack itself. The cost is steep and standing: crawling, storing, and continuously reranking hundreds of billions of pages, then running a 70B model on specialized hardware for every answer, is a bill that has outrun the company’s revenue so far. The benefit is that retrieval quality became a knob Perplexity turns rather than one it waits on a vendor to turn7.
Decision 3: make ranking a cheap-then-expensive cascade. Quality ranking and low latency pull against each other. Perplexity’s answer is a hybrid funnel: cheap scorers drop the obvious misses first, then the expensive cross-encoder judges only the survivors, so retrieval still lands inside the 100-millisecond budget. The catch is recall. A candidate the cheap scorers throw out never reaches the cross-encoder, so an early filter set too tight silently drops answers the reranker would have caught. Tuning that cut point is a permanent maintenance cost.
The Honest Take
What works is the strict-grounding bet. Tying every sentence to a retrieved source is a structural fix for hallucination rather than a slogan, and it is why people reach for Perplexity on questions where being wrong has a cost. Owning retrieval compounds it, because each of the four hallucination causes becomes a knob Perplexity can turn rather than a vendor it can only email.
What is still unsolved is that grounding reduces hallucination, it does not end it. Srinivas says as much: the model can still misread a good passage, the index can still serve a thin one, and a citation only proves a sentence has a source; it does not prove the source is right or that the model summarized it faithfully. A footnote is a pointer, and pointers can aim at the wrong thing.
The elephant in the room is opacity. Perplexity publishes almost no hard backend numbers. We know the index is “hundreds of billions of pages” and the latency budget is “about 100 milliseconds,” but there is no public figure for queries per second, no per-stage latency breakdown, no disclosed reranker model or stage count, no named vector store. Plenty of write-ups invent that precision; this one stays with the figures Perplexity has actually published.
Could a smaller team build this? The pattern, yes. Hybrid retrieval, a cross-encoder rerank stage, strict grounding, and cited generation are reachable today with Vespa or comparable open tools over a focused corpus, the path How DoorDash Built Their RAG System walked. What does not transfer is the open web. Crawling hundreds of billions of pages and continuously reranking them is a standing infrastructure commitment: a dedicated team, a crawl budget, and years of tuning that no small team can shortcut.
The One Thing to Remember
The model is the smallest part of this story. Sonar is a fine-tuned 70B, the kind thousands of teams can run, and it is not what makes Perplexity hard to copy. The moat is everything wrapped around it: an owned index of hundreds of billions of pages, a rerank funnel that lands in 100 milliseconds, a planner that decomposes the hard questions, and a grounding rule strict enough that the model would rather say “I do not know” than invent. An answer engine is mostly retrieval, and the sentence generator is the last and smallest step.
💬 Building RAG over your own corpus and deciding how hard to ground it? Tell me in the comments where your retrieval falls down. I read every one.
FAQ
How does Perplexity’s search engine work?
Perplexity is a retrieval-augmented answer engine. For each question it searches its own index of hundreds of billions of pages, narrows the results through a funnel of fast lexical and embedding scorers and then cross-encoder rerankers, assembles the top passages into a prompt, and has its Sonar model write an answer with a citation on every sentence, drawing only from what was retrieved.
What model does Perplexity use?
Perplexity’s default answer model is Sonar, fine-tuned from Meta’s Llama 3.3 70B for factuality and served on Cerebras hardware at about 1,200 tokens a second. It can route to other models too, but Sonar is tuned for the specific job of writing concise, cited answers from retrieved passages rather than from memory.
Is Perplexity just a wrapper on Google?
No. Perplexity runs its own crawler, PerplexityBot, and its own search index of hundreds of billions of pages, the same index it now sells through its Search API. It also licenses third-party crawlers, so it uses hybrid sourcing, but the index and ranking stack are its own rather than a resold Google or Bing feed.
How does Perplexity reduce hallucinations?
Through strict grounding. The model is instructed to use nothing beyond the retrieved passages, to cite every sentence, and to say it lacks enough information when the sources fall short. Because most hallucination traces to weak retrieval, Perplexity also owns the index to keep results fresh and relevant. Grounding lowers the hallucination rate without eliminating it.
🔜 Tuesday: Agent Prompt Engineering, the patterns that keep an agent on task instead of improvising.
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs, arXiv 2406.10279 (USENIX Security 2025)
Aravind Srinivas at Bloomberg Tech Summit, June 2025
Lex Fridman Podcast #434, Aravind Srinivas, June 2024
Introducing the Perplexity Search API, Perplexity, September 2025
Cerebras Powers Perplexity Sonar with Industry’s Fastest AI Inference, Cerebras, February 2025
Breakout Agents: Perplexity Pro Search, LangChain, February 2025
Perplexity’s 2024 revenue and costs, reported by The Information, May 2025