

How Anthropic Built Multi-Agent Deep Research
15x the tokens, 90.2% better answers, and the three decisions that make it work.

🧭 Part 13 of the 🤖 Agents course
You hand Claude a question: “Find every board member of every Information Technology company in the S&P 500.” A single agent will work through it the way you would: search company one, scrape the result, search company two, repeat. By the time it finishes, you’ve spent an hour and burned through the context window twice. There are 65 companies on that list. That’s at least 65 sequential web searches plus a few hundred follow-ups to chase ambiguous names. The query is breadth-first by nature, and a single agent can only walk it sequentially, one company at a time.
Anthropic shipped a different answer in April 2025: a Research feature1 that spawns parallel subagents, each with its own context window, each chasing one independent thread. On their internal eval, this setup beat single-agent Claude Opus 4 by 90.2%. The cost: roughly 15x the tokens of a normal chat2.
This issue is about what the architecture is, when the 15x cost is worth paying, and the production decisions that separate 'neat demo' from 'shipped to millions.'
TL;DR
What it is: Claude’s Research is an orchestrator-worker system: a lead agent plans, spins up 3-5 specialized subagents in parallel, and synthesizes their findings with a separate citation pass.
What it solves: Breadth-first research questions where the answer requires exploring many independent paths at once and the total information exceeds a single context window.
Performance: 90.2% improvement over single-agent Claude Opus 4 on Anthropic’s internal research eval. 90% reduction in research time on complex queries.
Cost: ~15x the tokens of a chat interaction. Token usage alone explains 80% of performance variance.
Lesson: Architecture follows task structure. Multi-agent only wins when the task decomposes into independent parallel threads
The Orchestrator-Worker Pattern
Orchestrator-worker predates LLMs by decades. Query planners in distributed databases fan work out to shard workers. Kernels schedule threads. Every engineering team has a tech lead who decomposes the sprint and hands tickets to engineers. One coordinator breaks the problem apart, workers handle the pieces in isolation, the coordinator stitches the result back together. The novelty in 2025 is that every node in the system is an LLM making routing decisions on the fly.
The other major pattern is the swarm or peer-to-peer model, where agents talk directly to each other and share state, often through a common message bus or scratchpad. Swarm models are flexible but hard to reason about. Orchestrator-worker constrains the topology. Workers never talk to each other. Every decision about what comes next lives in the orchestrator.
The decision that matters in any multi-agent design is the isolation boundary: what does each subagent need to know about what the others are doing? Anthropic’s bet is that for research, the answer is “almost nothing.” Each subagent gets a self-contained task description, an output format, and a fresh context window. It doesn’t know the other subagents exist. It cannot coordinate with them mid-task. It’s what lets the subagents run in true parallel and what keeps the lead agent’s context window from drowning in cross-talk.
Cognition’s Don’t Build Multi-Agents3 argues the opposite: parallel subagents make independent decisions, and independent decisions on the same problem produce conflicting outputs. Their canonical example: a Flappy Bird clone request decomposed into subtasks. Subagent A builds a Super Mario background. Subagent B builds a bird with no consistent art style. Both technically completed their assigned tasks. Neither saw the original “Flappy Bird” framing, so the implicit “match the source game’s aesthetic” decision was lost in delegation. Both teams are right inside their own domain. Cognition is solving for shared-state tasks where isolation breaks things. Anthropic is solving for independent-thread tasks where isolation is the whole point. The task picks the architecture.
Why Anthropic Built This
Anthropic launched the Research feature in April 2025 as a research extension to Claude. The structural problem they hit is the one every research workflow hits: you can’t predict the path in advance, because each new fact reshapes the next question. A static pipeline (”retrieve top-k, summarize, return”) fails the moment the user asks anything that requires following a thread.
Their first attempt was a single agent with bigger context and more tool calls. It hit two limits. The first one was sequential time: a query that needs 50 web searches takes 50 sequential round-trips. The second limit was the 200K-token context limit on Claude Opus 4. Past that limit, the context gets truncated, and the agent loses the plan it made in turn one.
Anthropic’s architecture answers the structural problem: one Claude plans the search, several Claudes do the search in parallel, and a separate Claude with its own context window verifies every citation before anything reaches the user.
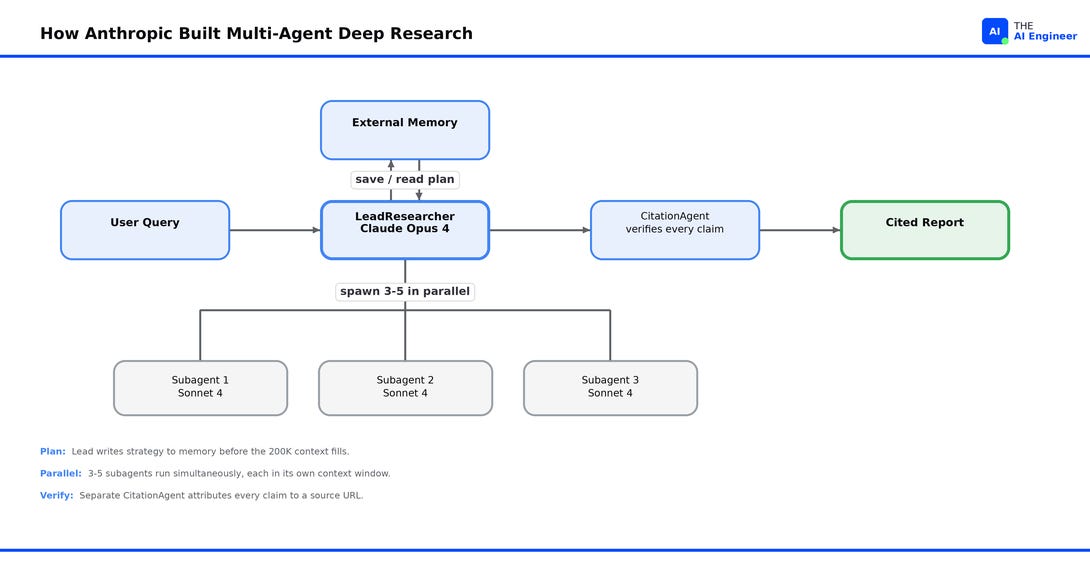
LeadResearcher (Claude Opus 4) receives the query.
LeadResearcher plans. It uses extended thinking mode4 to draft a strategy, decide breadth vs depth, and write the plan to external memory before context fills.
LeadResearcher spawns 3-5 Subagents (Claude Sonnet 4) in parallel. Each gets a self-contained task: an objective, an output format, a tool list, and a clear boundary on when it’s done.
Each Subagent searches independently. Each one calls 3+ tools in parallel inside its own context window, evaluates results with interleaved thinking5, and returns a condensed summary to the lead.
LeadResearcher synthesizes. It reads the summaries, decides whether more research is needed, and either spawns another wave of subagents or moves to the next step.
CitationAgent (a separate pass) attributes claims. It walks through the final report and the source documents, attaching each claim to a specific URL. Single-agent systems can’t separate confident from correct. This can.
🔍 Deeper Look: The deeper engineering lesson is separation of concerns for high-stakes tasks, and it generalizes beyond citations. A single agent doing both "decide what to write" and "verify every citation" produces what Anthropic calls "the game of telephone": by the time the report is drafted, the source URLs have been condensed and re-summarized through several subagent returns, and the lead agent is reconstructing citations from memory. A separate CitationAgent reads the raw documents AND the final report, so it checks claims against ground truth instead of the lead agent's recollection of it.
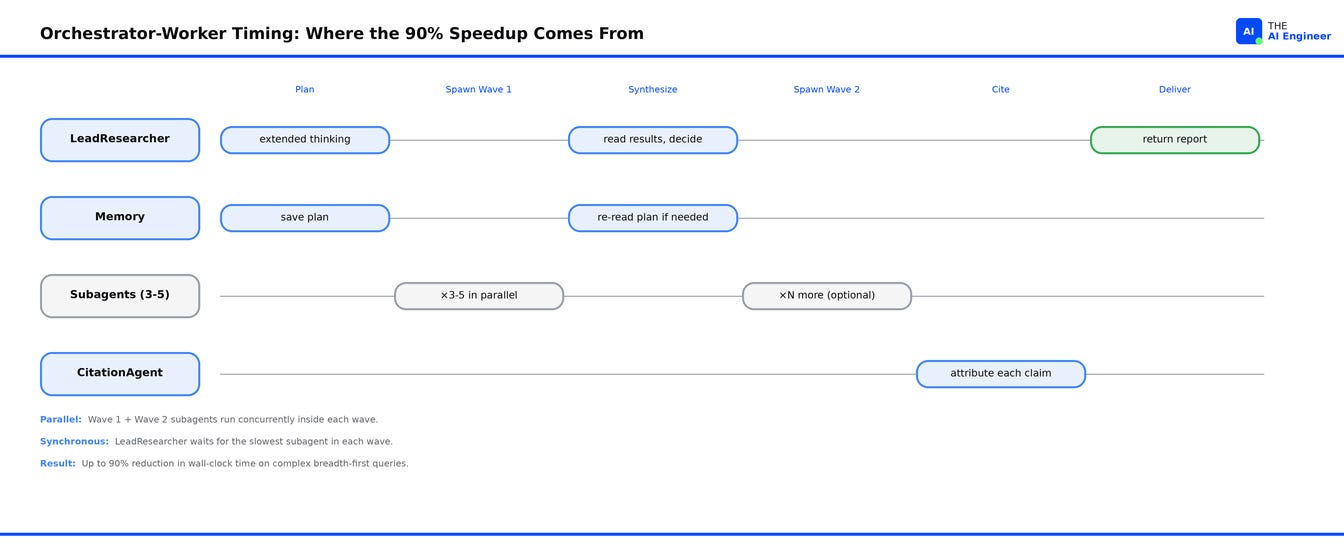
How the components interact across a single session, with the LeadResearcher blocking on the slowest subagent in each wave:
The Engineering Decisions
Decision 1: Externalize state to memory
The decision. When the LeadResearcher’s context approaches the 200K-token limit, it writes the plan to external memory, hands the next phase to subagents with fresh context windows, and reads the plan back when needed.
The context. Research tasks can run for hundreds of turns. At Claude Opus 4’s 200K context limit, a long-running research agent that holds every tool result in conversation history will hit truncation, and the plan written in turn 1 is gone by turn 40.
The tradeoff. Coordination complexity. State lives in two places now: in-context for short-lived decisions, in external memory for long-lived plans. The agent has to decide every turn whether to use what's in context or read from memory.
The limitations. External memory works for state that’s structured and infrequently mutated (the plan, the user’s original question, the high-level strategy). It does not work for fast-changing in-flight state across many parallel agents. There’s no shared transactional store; if two subagents need to coordinate on a finding mid-search, this architecture can’t help them. Cognition’s critique of multi-agent systems lands hardest exactly here.
The result. Research sessions that would otherwise hit context truncation at turn 40 can now run to turn 200+. The LeadResearcher’s plan survives the entire session because it lives outside the context window.
My take. This decision is what lets the whole architecture exist, and it’s worth borrowing even in single-agent systems. We covered the broader pattern in What is Agent Memory?.
Decision 2: Run subagents in parallel
The decision. The LeadResearcher spawns 3-5 subagents simultaneously. Each runs in its own context window and never sees what the others are doing.
The context. Early versions of the system ran searches sequentially. The sequential approach hit two limits. The first was latency: 50 sequential web searches at ~2 seconds each is ~100 seconds before the agent even starts synthesizing. The second was context bloat: tool results crowded out the original query within 20 searches. Parallelism solves both.
The tradeoff. Coordination. A subagent that doesn’t know what its peers are doing will sometimes duplicate work. One of Anthropic’s early systems had a subagent investigating the 2021 automotive chip crisis while two others duplicated work on current 2025 supply chains. The fix was better task descriptions in the orchestrator’s delegation prompt: explicit objectives, explicit boundaries, explicit “don’t research X, that’s another subagent’s job.”
The limitations. Parallel subagents only help if the subtasks are truly independent. If subagent B needs subagent A’s findings to do its job, parallelism degenerates into expensive serial execution with extra overhead. Anthropic’s blog is direct: “domains that require all agents to share the same context or involve many dependencies between agents are not a good fit for multi-agent systems today.” Coding, debugging, and most agentic workflows fail this test. Research passes it.
The result. Up to 90% reduction in research time on complex queries that previously ran serially. Wall-clock per wave drops from the sum of subagent times to the max of subagent times.
My take. Parallel subagents work because each one gets its own context window. Total tokens spent on the query goes up, even though no single context window gets bigger. Anthropic found that token spend alone, more than any other variable, predicts how good the final answer is.
Decision 3: Evaluate outcomes with LLM judges
The decision. Anthropic evaluates the system using LLM-as-judge against a rubric (factual accuracy, citation accuracy, completeness, source quality, tool efficiency). They do not check whether the agents followed a “correct” sequence of tool calls.
The context. Multi-agent systems are non-deterministic by design. Given the same query, two runs may use different subagent counts, different tools, different search orders, all reaching the same valid answer. Traditional evals that score on the path (”did the agent call tool X then tool Y?”) fail because there is no single correct path. We covered this pattern in detail in Why AI Agents Keep Failing in Production.
The tradeoff. LLM judges are themselves probabilistic. A judge that scores too leniently masks regressions; a judge that scores too strictly punishes valid alternative paths. Anthropic experimented with multiple judges per output and found a single judge with a clear rubric was both cheaper and more aligned with human grading than a panel approach.
The limitations. LLM judges work well when the rubric is clear (factual claims have verifiable answers; citations have URLs that exist or don’t). They work poorly when the task is creative, subjective, or has no ground truth. Research with citations passes this test. Open-ended summarization fails it. Human testers also caught failure modes the LLM judge missed, including a subtle bias where early agents preferred SEO-optimized content over higher-quality but lower-ranked sources like academic PDFs.
The result. Hundreds of evals run cheaply per change. Anthropic recommends starting with about 20 test cases. Early in development, any change you make moves the score so much that you don’t need a big test set to see whether it helped.
My take. LLM-as-judge is one of the most-misused patterns in agent eval. Anthropic’s rubric has five explicit criteria: factual accuracy, citation accuracy, completeness, source quality, tool efficiency. With those criteria spelled out, a single Sonnet call returns scores that match human graders. Teams who skip the rubric and just ask “is this good?” get noise and blame the LLM.
The Tradeoffs
The architecture only pays off for tasks in the upper-right quadrant of this map: high-value queries that decompose into independent parallel threads.
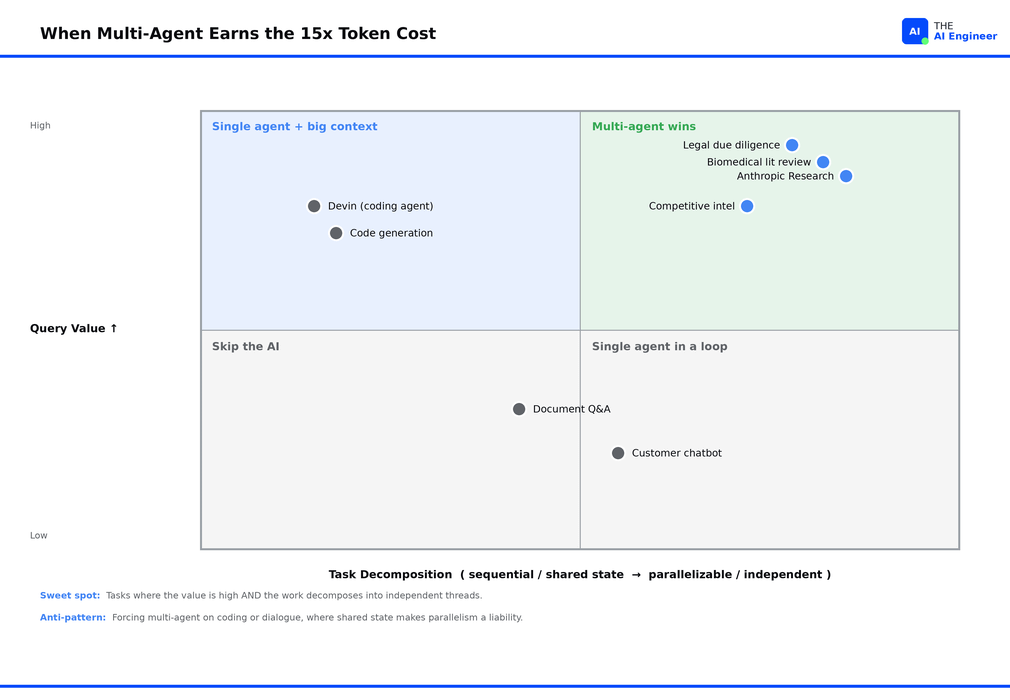
The LeadResearcher executes subagent waves synchronously, so a single slow subagent stalls the entire wave; asynchronous execution is on the roadmap but the coordination problem (result ordering, state consistency, partial failures) is unsolved. The topology has no migration path for tasks with shared state across agents, which means coding, dialogue, and most agentic workflows fall outside the sweet spot.
A single Research session can use millions of tokens, dollars per query at current Claude pricing. The economics only work for high-value research: legal due diligence, competitive intelligence, biomedical literature review. Consumer-grade Q&A cannot absorb the multiplier. The 15x baseline also compounds when something misbehaves: a subagent that recursively spawns more subagents, or a tool that returns oversized results, can multiply a single query’s cost by another 10x or more. The published architecture has no circuit breakers or per-run caps.
Can a smaller team reproduce this? The orchestrator-worker pattern, the CitationAgent pattern, and the external-memory pattern are all reproducible. What isn’t is the prompt engineering. Anthropic spent weeks watching agents fail in simulations and rewriting delegation prompts to fix specific failure modes. They published the principles (”think like your agents,” “scale effort to query complexity,” “teach the orchestrator how to delegate”) but not the prompts. Expect 2-3 months of iteration before your version stops spawning 50 subagents for a one-line question. Their Claude cookbook prompts are the closest public reference for the basic agent workflow patterns.
🏗️ Engineering Lesson: You can use three patterns from this architecture without building a multi-agent system at all. (1) Externalize state to memory before context fills. (2) Isolate workers with self-contained task descriptions. (3) Verify high-stakes outputs (citations, code review, factual claims) with a separate pass. The full orchestrator-worker topology is expensive and only justified when the task is provably breadth-first. Most production systems can apply these three patterns inside a single agent and capture the reliability gains without the 15x token cost.
The Bottom Line
Agent architecture is a token-spending strategy. You spend dollars to buy parallelism, and the spend only cashes out when the task decomposes into independent threads. Anthropic’s own line is the cleanest version: “Multi-agent systems work mainly because they help spend enough tokens to solve the problem.” Before building one of these systems, the question to answer is whether your task has enough independent threads to make the parallelism pay for itself.
If you’ve built anything multi-agent in production, what broke first?
Where to Next?
📖 Go Deeper: The AI Agents Stack (2026 Edition). The full layered view of how agents get assembled in production. Orchestrator-worker is one pattern at the top layer; the bottom seven matter just as much.
🔗 Go Simpler: What is an AI Agent?. Start here if any of the loop, tool, or context-window references felt too fast.
🔀 Go Adjacent: Why AI Agents Keep Failing in Production. The three production patterns that break first, and how Anthropic’s architecture sidesteps each one.
If you're transitioning into AI engineering, How to Break Into AI Engineering in 2026 is a free 34-page PDF roadmap, covers everything from market data to monthly transition milestones, organized by your starting role.
🔜 Tuesday: The Open-Source Agent Toolkit in 2026. What you’d actually use to build a multi-agent system in 2026 without the Anthropic API bill.
Anthropic Research feature launch (Apr. 2025)
How we built our multi-agent research system (Jun. 2025)
Don’t Build Multi-Agents (Jun. 2025)
Extended thinking (Anthropic docs)
Interleaved thinking (Anthropic docs)
This really landed for me — "multi-agent works mainly because it spends enough tokens to solve the problem." I built a little personal deep-research setup on basically that premise, and the caveats you list are the exact walls I hit.
The runaway-cost one especially. I ended up just not letting subagents spawn their own subagents — enforced in the orchestration layer, not begged for in a prompt. Doesn't give me a real per-run cost cap (still missing that one too), but it kills the scariest multiplier by default.
Same instinct on verification — a separate verifier that grep-checks citations against the source, instead of an LLM grading its own homework.
The thing I keep chewing on: did Anthropic hard-ban recursion internally, or let agents spawn and rein it in some other way? Curious how they landed on it.
The parallelization insight here is what separates shallow agentic implementations from ones that actually scale. The 15x token cost sounds alarming but the 90.2% answer quality improvement tells the real story - for knowledge-intensive enterprise use cases, the ROI math flips quickly when you factor in analyst time saved. The orchestrator-subagent pattern Anthropic settled on is also the one I've seen work best in production deployments. Really useful breakdown of the design decisions.