

H100 vs H200 vs B200
Which GPU is worth the premium right now?

🧭 Part 8 of the ⚡ Hardware & Inference course
You scoped a 70B model deployment six months ago. You picked the H100 because it was the GPU everyone was talking about, signed a one-year reserved contract, and felt good about it. Then the H200 launched with 76% more memory, and Blackwell B200 followed with a spec sheet that made your H100 look pedestrian. Now your CFO is asking why the per-token cost is 3x what the team next door reports, and your reserved capacity has eleven months left.
Here’s how to actually decide.
TL;DR
H100: fits-in-80GB workloads where $/token wins. Deepest software stack, cheapest on every cloud. Skip it if you need 100B+ models on one GPU at usable precision.
H200: memory-bandwidth-bound inference and 70-100B models past 80 GB. Drops into the Hopper stack with no kernel re-tuning. Skip it if you’re compute-bound, since the compute is identical to H100.
B200: new FP4 training runs and rack-scale inference. Fifth-generation Tensor Cores and a native FP4 path, though the software is still maturing. Skip it if you’re on a Hopper-only stack or can’t handle the 1,000W TDP.
Bottom line: H100 if your model fits in 80 GB and batches are healthy, H200 if decode is memory-bandwidth-bound (most inference is), Blackwell if you need FP4 throughput or rack-scale memory. Run a 24-hour test on each through CoreWeave or Lambda before signing anything.
Here’s how to actually decide.
What Are We Even Comparing?
New to GPU internals? What is a GPU? breaks down tensor cores, HBM, and the memory-bandwidth wall this whole comparison turns on.
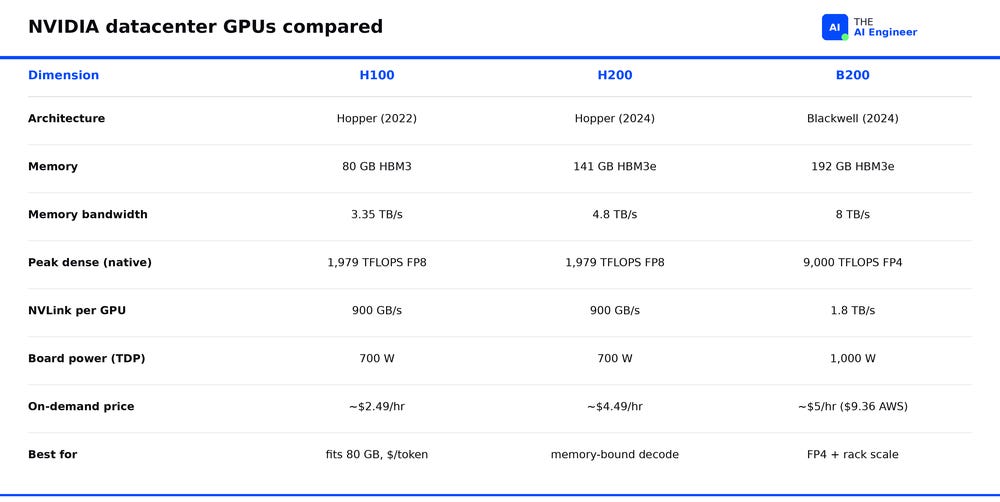
These are NVIDIA’s three current datacenter GPUs, and they span two architectures. The H100 and H200 are both Hopper; the H200 adds memory to the same silicon. The B200 opens the Blackwell generation with 2.6x the transistors and a native 4-bit number format. So a Hopper-to-Hopper upgrade helps only when memory is your constraint, while the jump to Blackwell is what moves compute and precision throughput.
The H100 launched in March 2022 on the Hopper architecture, with fourth-generation Tensor Cores and the Transformer Engine. The Transformer Engine tracks each tensor’s numeric range as it computes and drops it to FP8 when the values fit, holding 16-bit precision when FP8 would cost accuracy. This GPU scaled the first wave of frontier LLMs. The TAE deep dive on NVIDIA covers how this generation became the company’s revenue engine: What Does NVIDIA Actually Do?.
The H200 is the same Hopper GH100 die with a bigger memory subsystem: 141 GB of HBM3e1 at 4.8 TB/s, replacing the H100’s 80 GB of HBM3 at 3.35 TB/s. Identical compute, much more room.
The B200 puts two GPU dies in one package, linked by a 10 TB/s die-to-die interconnect, with fifth-generation Tensor Cores and 192 GB of HBM3e at 8 TB/s. Its native FP4 format drives the inference gains: 4-bit floating point, half the storage of FP8 at roughly 2x the throughput where accuracy holds. GPTQ vs AWQ vs GGUF: Which 4-Bit to Pick in 2026 breaks down the formats this hardware path runs on. The bigger story is what NVIDIA built on top: the GB200 NVL72 packs 72 B200 GPUs and 36 Grace ARM CPUs into one liquid-cooled rack that behaves like a single massive GPU.
⚠️ Confusion Alert: “Blackwell” could mean the B200 SKU (one GPU you rent by the hour), the GB200 Superchip (two B200s plus a Grace CPU on one board), or the GB200 NVL72 (a 72-GPU liquid-cooled rack). Three products, three price points. The breakdowns below cover the rentable single-GPU SKUs (H100 SXM5, H200 SXM, B200). Rack-scale Blackwell gets its own sidebar at the end.
The Bottleneck
Every datacenter GPU choice reduces to four decisions, in this order:
Memory capacity (HBM in GB): does your model fit on one GPU at your target precision, or are you paying the cost of model parallelism2
Memory bandwidth (TB/s): how fast can the GPU move weights from HBM into the tensor cores during decode? This is the bottleneck for most production inference.
Compute throughput (TFLOPS at your target precision): how many useful operations per second at FP8, FP16, or FP4? Matters most for training and prefill.
NVLink scale (GB/s, GPUs per domain): how fast can multiple GPUs talk to each other when one isn’t enough?
Everything else (power, form factor, software stack maturity, pricing volatility) is downstream of these four.
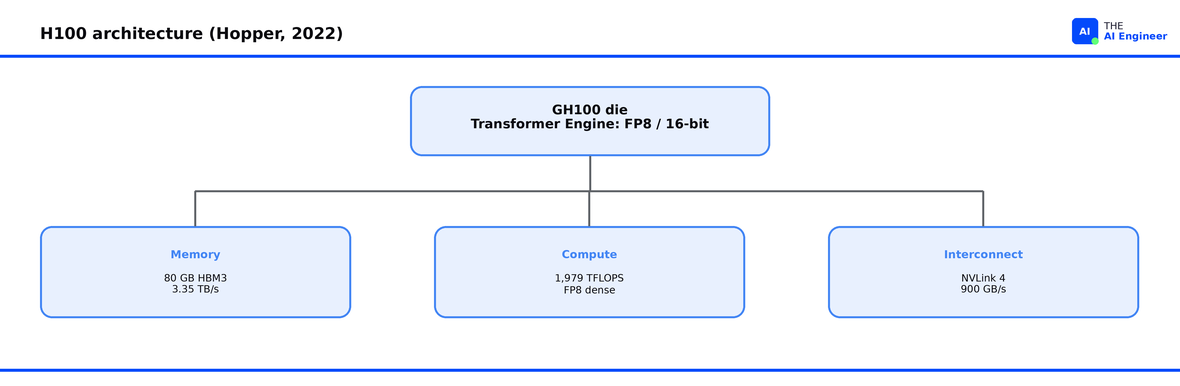
H100
In one sentence: The Hopper-generation workhorse that scaled the first wave of frontier LLMs.
👍 The good:
80 GB HBM3 at 3.35 TB/s memory bandwidth and 1,979 TFLOPS FP8 dense3, enough to train and serve 70B-parameter models in production4.
The Transformer Engine that made FP8 training practical at scale, shipped first on this Hopper generation5.
The cheapest of the three on every cloud: RunPod and DataCrunch list it at $1.99/GPU/hr on-demand, Lambda at $2.49/GPU/hr, with spot rates as low as $1.49/GPU/hr on Vast.ai67.
The deepest software stack of any generation: every major serving engine (vLLM, TensorRT-LLM, SGLang, TGI) has its kernels tuned for H100 first, with FP8 paths that have shipped in production for over two years.
👎 The bad:
80 GB caps single-GPU inference: a Llama 3.1 70B model at FP8 needs roughly 70 GB just for weights, leaving thin KV cache headroom and forcing tensor parallelism for anything larger.
No FP4 support: Hopper lacks the precision tier that gives Blackwell its biggest throughput gain8.
NVLink 4 at 900 GB/s bidirectional: half the per-GPU interconnect bandwidth of NVLink 5 on Blackwell, capping how well a multi-GPU server scales for tensor-parallel workloads9.
🎯 Best for: Production inference of models that fit comfortably in 80 GB, where you care more about $/token than peak throughput.
⚠️ The ceiling: Migrate away when one model needs more than 80 GB at usable precision, when memory bandwidth (not compute) becomes your decode bottleneck, or when your competitors deploy FP4 and start undercutting your per-token cost.
📡 Practitioner signal: NVIDIA still submits H100 results in every MLPerf round two years after launch, and Hopper ran every benchmark in the latest inference suite, a signal that the software stack keeps getting investment long after the chip shipped1011.
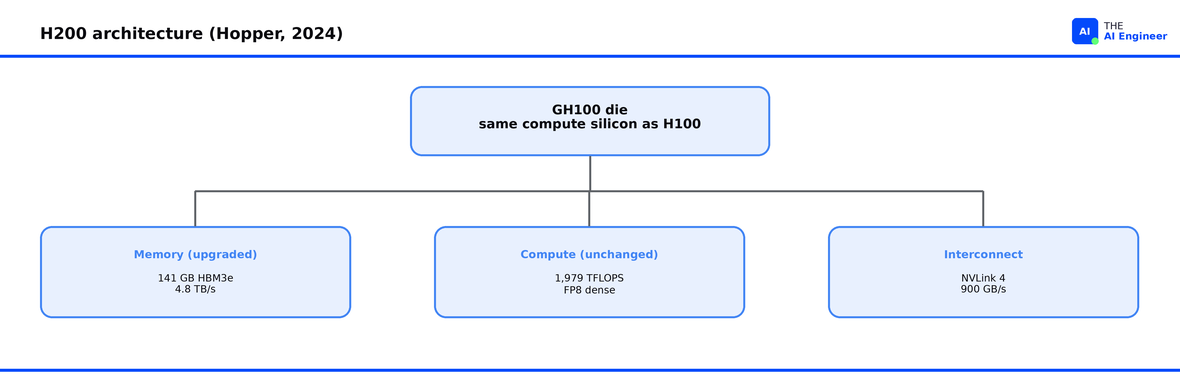
H200
In one sentence: A Hopper memory upgrade that turns the same compute into a much faster decode engine.
👍 The good:
Same silicon, more memory: 141 GB of HBM3e at 4.8 TB/s, a 76% capacity jump and 43% bandwidth jump over H100 on the identical GH100 die12
70B models fit on one GPU: the 141 GB leaves usable KV cache headroom, so you skip the cross-GPU communication tax that drags H100 decode latency on the largest models that fit
Drop-in upgrade: the shared Hopper architecture runs existing TensorRT-LLM, vLLM, and SGLang deployments unchanged, with no kernel re-tuning
43% faster decode: a 70B FP8 model at batch=1 hits around 430 tokens/sec versus 300 on H100, straight from the bandwidth jump13
👎 The bad:
No compute gain: the GH100 die carries the same 1,979 TFLOPS FP8 dense as H100, so any workload bottlenecked on raw compute sees zero improvement14
Still no FP4: the Hopper-generation Tensor Cores skip the 4-bit format that drives Blackwell’s biggest throughput gains
You pay for bandwidth you may not use: Lambda lists H200 at $4.49/GPU/hr against H100 at $2.49, a roughly 80% premium that buys nothing for a compute-bound job15
🎯 Best for: Memory-bandwidth-bound inference (most decode workloads are) and any model that needs more than 80 GB at production precision.
⚠️ The ceiling: Migrate away when FP4 enters your stack, when your model exceeds 141 GB at production precision, or when training compute (not inference memory) becomes your dominant cost.
📡 Practitioner signal: An independent 8-GPU benchmark clocked H200 at 1.83-2.14x H100 throughput on long-context inference (16K tokens). Under that load H200 held 53% of its throughput versus H100’s 36%, the extra bandwidth paying off exactly where KV-cache traffic dominates16.
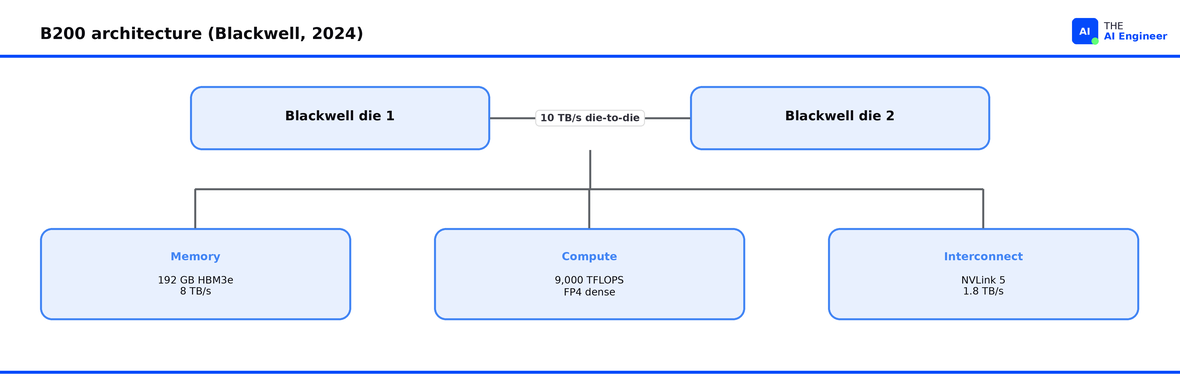
B200
In one sentence: The first Blackwell GPU, pairing 192 GB of memory and native FP4 with a dual-die design that scales up into the GB200 rack.
👍 The good:
192 GB at 8 TB/s: the HBM3e runs 2.4x the bandwidth of H100 and 1.67x the H200, on a dual-die package of 208 billion transistors (vs 80 billion on H100) joined by a 10 TB/s die-to-die link17
Native FP4, up to 4x inference: fifth-generation Tensor Cores hit 9,000 TFLOPS FP4 dense and deliver up to 4x the per-GPU inference throughput of an H100 on Llama 2 70B in MLPerf Inference v4.118
Double the interconnect: NVLink 5 moves 1.8 TB/s bidirectional per GPU, doubling the Hopper scaling headroom for tensor-parallel and pipeline-parallel workloads19
~2x faster training: B200 trains GPT-3 175B about 2x faster than H100 and runs a Llama 2 70B fine-tune about 2.2x faster, per MLPerf Training v4.120
👎 The bad:
1,000W TDP: B200 draws far more than the 700W H100 and H200, so existing H100-class datacenters cannot drop one in without cooling and power upgrades
FP4 software is young: vLLM, TensorRT-LLM, and SGLang ship FP4 support today, but the production tuning runs shallower than Hopper’s two-year head start
Hyperscaler pricing inverts: AWS Capacity Blocks list B200 near $9.36/GPU/hr, more than 2x H100 on the same cloud, though neo-cloud rates ($3.99 on DataCrunch, $4.99 on Lambda and RunPod) narrow the gap2122
🎯 Best for: New training runs and inference workloads where FP4 amenability or the 192 GB memory ceiling justifies the higher per-hour cost.
⚠️ The ceiling: The single-GPU B200 hits its ceiling when one model needs to span more than one rack’s worth of unified memory at full precision, or when cross-node communication on a standard 8-GPU HGX server becomes the bottleneck. That’s where the GB200 NVL72 takes over.
📡 Practitioner signal: Lambda’s 8-GPU HGX B200 system picked up as much as 9% more Llama 3.1 8B throughput from a pure CUDA 12.9-to-13.1 software upgrade, no hardware change, evidence that the Blackwell stack is still gaining free performance as it matures23.
The Decision Framework
The specs side by side make the gap obvious. The H100 to H200 jump is a memory upgrade: capacity, bandwidth, and price move, everything else holds. The H200 to B200 jump is a generation change: new architecture, FP4, double the interconnect, far more transistors.
The flowchart runs the bottleneck questions in priority order. Start with capacity, if your model doesn’t fit in 80 GB at your precision, the H100 is out. From there, FP4 or more than 141 GB means a B200, anything else means an H200. If your model does fit in 80 GB, look at bandwidth next. Memory-bandwidth-bound decode runs faster on the H200. Everything else runs cheapest on the H100.
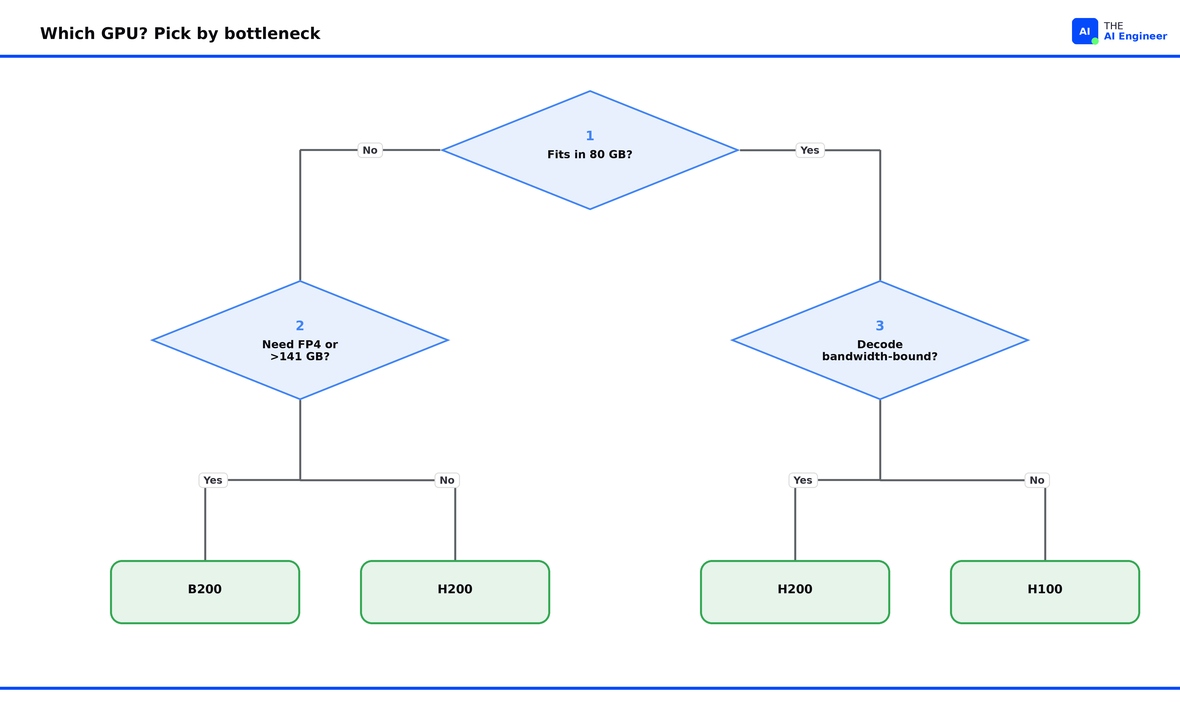
The One Thing to Remember
Most GPU regret traces back to one mistake: buying for peak compute when the workload was memory-bandwidth-bound the whole time. Each of these three chips clears a different bottleneck, and price climbs faster than any single spec. Find the resource your decode loop or training run starves for first, and buy the chip that clears it.
Where to Next?
📖 Go Deeper → The LLM Serving Showdown: vLLM vs Ollama vs SGLang vs TensorRT-LLM: what runs on these GPUs in production
🔗 Go Simpler → What Does NVIDIA Actually Do?: the company behind the silicon
🔀 Go Adjacent → Which NVIDIA GPU Do You Actually Need? (coming soon).
💬 What’s actually deployed in your stack right now, and what made you pick it? Reply or comment. Curious what the real production mix looks like.
🗺️ If you are transitioning into AI engineering, How to Break Into AI Engineering in 2026 is the full roadmap on getting there
🔜 Tuesday: Semantic Search. Why your keyword search is failing and what to swap in.
High Bandwidth Memory, third generation, stacked directly next to the GPU die
Splitting weights across multiple GPUs and paying for the cross-GPU communication on every forward pass
3,958 with structured sparsity, the hardware skipping zero weights in a 2-of-4 pattern
NVIDIA H100 Tensor Core GPU product page (May 2026)
gpu.fm Cloud GPU providers compared 2026 (Mar 2026)
Silicon Analysts cloud GPU pricing tracker (Apr 2026)
NVIDIA Blackwell architecture page (May 2026)
NVIDIA Blackwell architecture page (May 2026)
NVIDIA H200 product page (May 2026)
Spheron NVIDIA H200 Specs (May 2026)
Spheron NVIDIA H200 Specs (May 2026)
gpu.fm Cloud GPU providers compared 2026 (Mar 2026)
NVIDIA Blackwell B200 datasheet (PDF) (Mar 2024)
NVIDIA Blackwell architecture page (May 2026)
Silicon Analysts cloud GPU pricing tracker (Apr 2026)
gpu.fm Cloud GPU providers compared 2026 (Mar 2026)
Lambda's MLPerf Inference v6.0 results (Apr 2026).
The hardware moves so fast that picking the right GPU is starting to feel as much like a timing decision as a technical one